
CTO下午茶:化繁为简,面面俱到
ZD至顶网网络频道 03月07日 综合消息:经常接触不同行业的 CTO,我发现谈到 IT 系统,大家关注的方向往往差异很大。有时,即使是处在同一行业,也会因企业规模的不同而各有侧重。
例如,制造行业较多关注的是整体 IT 的成本,一直到未来 3~5 年内的 TCO(Total Cost of Ownership,即整体拥有成本);医疗行业,比如医院,更在意整体应用系统的稳定性、可管理性和安全性,毕竟医院的很多临床业务应用直接关系到患者的身心健康甚至生命安危;金融行业,比如银行、证券,则更聚焦在 IT 系统的安全性、性能表现、以及未来随业务扩展的平滑和敏捷性,因为对他们而言,安全、性能、速度意味着更好的服务体验。
然而,万变不离其宗。不改变 IT 架构,这些需求会越来越难以满足。
这并非夸大其辞,一位制药行业的 CTO 曾对我说:5年前,公司的业务规模只有 200 万销售额,1台服务器挂个磁盘阵列就轻松解决业务需求;现在,公司年销售额猛增至 30 多个亿,业务部门信息化应用的需求也越来越多,服务器和存储的数量快速增加,IT 架构扩展、运维管理的瓶颈越来越突出,IT 投资也逐年攀升!这位 CTO 坦言,这些问题已困扰他多时。
当企业规模开始迅速扩大,旧有的 “膏药式” IT 采购和部署方式的潜在弊端会被骤然放大——高昂的采购和维护成本、充满风险的扩展过程、不同品牌厂家带来的兼容性问题,甚至出现问题后的互相推诿……
有没有一项能化繁为简、面面俱到的强大技术呢?
有!超融合架构,在国外被称为 Hyperconverged infrastructure。从这个技术诞生之日起,它就备受 CTO 们的关注。
IDC 最新的一项全球范围调查数据[1] 表明,在 2014~2019 年间,超融合架构以近 70% 的年复合增长率,成为行业 CTO 们的战略投资首选。
超融合架构的最大特点就是将传统 IT 架构中彼此隔离的网络、服务器和存储系统基于虚拟化平台进行融合。不过,这种融合的能力不同厂商之间也是百家争鸣,各显神通。
然而从本质上讲,基本可以概括为组装型、开源型和商用型三类。
组装型:由用户自行采购设备,采购成本低,但达到最佳实践需要用户凭经验摸索,时间成本较高,最大的问题是兼容性隐患大、可靠性差、故障率高。
开源型:用户主要选择开源软件降低成本,主要的陷阱是软件的碎片化,一旦开源系统服务外包的核心人员离职,后续运维与维护就会面临很大的挑战。
商用型:用户选择信赖的厂商,采用商用软件+商用硬件,主流商用公司之间的互认证,保障了兼容性和可靠性。
而作为商用型的领头羊,思科希望达到更全面、更深入的融合,并非简单集成——思科 HyperFlex 超融合架构,目前也是业界唯一将网络、计算和存储系统、虚拟化软件进行深度融合的最完整超融合架构。
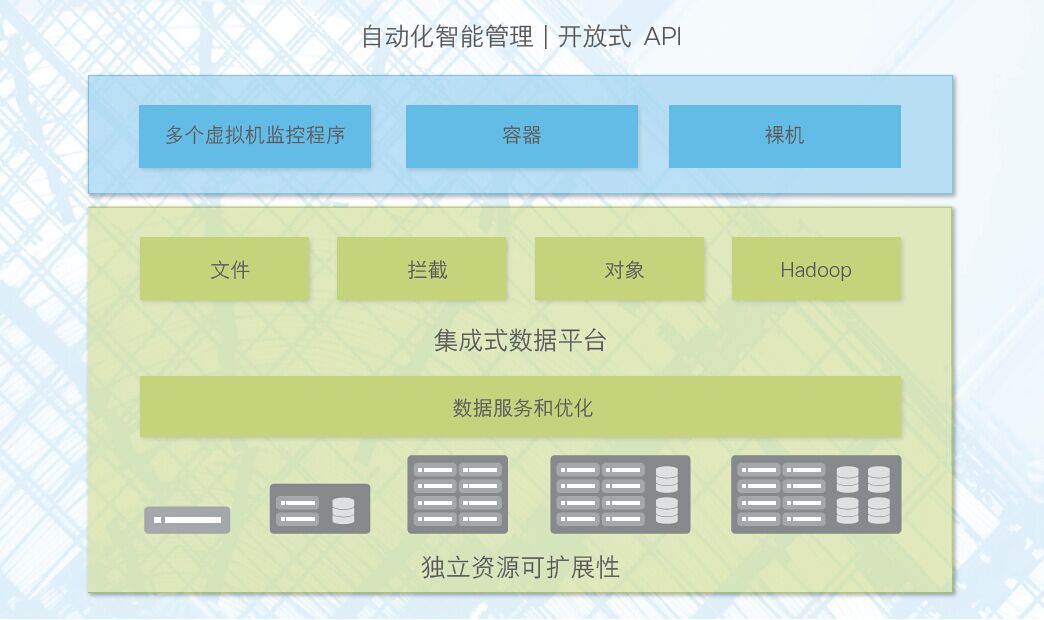
深度融合的特点,使思科 HyperFlex 超融合架构不仅具备强大的数据优化能力,而且支持统一管理,可面向更广泛的工作负载,从而实现管理的简化、扩展的平滑性和整体成本的收缩。
江苏利诚纺织集团近期建设的第二代 IT 系统,通过引入思科 HyperFlex 超融合架构,采购成本降低了约 15%,服务和管理成本降低了 30% 左右。不仅大幅降低了 TCO,提高了 ROI,IT 也更加高效,更能聚焦于业务创新。

记得金庸的《笑傲江湖》中,风清扬传授给令狐冲的 “独孤九剑”,把破解普天下所有兵器和拳脚功夫的招数,简化浓缩成九式。这和我们今天聊的思科 HyperFlex 超融合架构,颇有异曲同工之妙。
化繁为简,也正是驱动科技发展的有趣动力之一。

好文章,需要你的鼓励


人工智能落地“最后一公里”,戴尔工作站助力AI应用提速
英特尔携手戴尔以及零克云,通过打造“工作站-AI PC-云端”的协同生态,大幅缩短AI部署流程,助力企业快速实现从想法验证到规模化落地。

意大利ISTI研究院推出Patch-ioner:一个神奇的零样本图像描述框架,让电脑像人一样描述任何图像区域
意大利ISTI研究院推出Patch-ioner零样本图像描述框架,突破传统局限实现任意区域精确描述。系统将图像拆分为小块,通过智能组合生成从单块到整图的统一描述,无需区域标注数据。创新引入轨迹描述任务,用户可用鼠标画线获得对应区域描述。在四大评测任务中全面超越现有方法,为人机交互开辟新模式。

阿联酋MBZUAI发布PAN世界模型,AI仿真技术迎来突破
阿联酋阿布扎比人工智能大学发布全新PAN世界模型,超越传统大语言模型局限。该模型具备通用性、交互性和长期一致性,能深度理解几何和物理规律,通过"物理推理"学习真实世界材料行为。PAN采用生成潜在预测架构,可模拟数千个因果一致步骤,支持分支操作模拟多种可能未来。预计12月初公开发布,有望为机器人、自动驾驶等领域提供低成本合成数据生成。

MIT团队重磅发现:不配对的多模态数据也能让AI变得更聪明
MIT研究团队发现,AI系统无需严格配对的多模态数据也能显著提升性能。他们开发的UML框架通过参数共享让AI从图像、文本、音频等不同类型数据中学习,即使这些数据间没有直接对应关系。实验显示这种方法在图像分类、音频识别等任务上都超越了单模态系统,并能自发发展出跨模态理解能力,为未来AI应用开辟了新路径。
2017
03/07
11:43
分享
点赞

《2025 中国企业级 AI 实践调研分析年度报告》:深度剖析与价值洞察
Gartner:在中国构建AI软件工程技能的三大举措
阿联酋MBZUAI发布PAN世界模型,AI仿真技术迎来突破
Nvidia和Google支持的AI代码编辑器Cursor获23亿美元融资
Anthropic披露首例Claude模型参与的AI网络间谍活动
Cadence首款系统芯粒架构成功流片,助力物理AI发展加速
百度发布定制AI加速器响应国产芯片需求
VasEdge试用火热招募,降本增效机遇来袭
Infinidat InfiniBox G4系列升级重塑高端企业存储格局
Avalonia为微软MAUI跨平台应用方案带来Linux和浏览器支持
谷歌DeepMind发布SIMA 2智能体:游戏世界中学习迈向AGI之路
Infinidat G4系列升级重新定义高端企业存储格局
思科人工智能研究:97%的AI领导者实现规模化价值 基础设施决策成就领先优势
企业AI就绪安全网络架构,你跟上了吗?
思科携手英伟达推出面向 Neocloud、企业与电信行业的人工智能创新方案
拨开AI迷雾,思科《2025年人工智能就绪指数》揭示企业AI落地“真相”
思科人工智能研究:人工智能就绪型企业在价值竞赛中遥遥领先
思科发布业内最具扩展性与效能的51.2T路由系统 为分布式AI工作负载树立新标杆
思科任命Ben Dawson为亚太、日本及大中华区总裁兼销售高级副总裁
思科AI生态布局:成为企业AI转型的第一选择
思科的AI战略蓝图:连接好AI,守护住AI
思科科技创新AI峰会成功举办 并发布2025《网络安全就绪指数》
