
康普观点:2024年企业将面对的新技术、新挑战和新解决方案
康普RUCKUS大中华区总监 程俊邦
成功的企业从不会停止适应不断变化的商业环境。就像经验丰富的球队队长能够洞察赛场,从而发现机会、权衡风险一样,主动出击的企业才能蓬勃发展。无论是在体育界还是在商界,在等待最佳行进路线逐渐明朗的过程中,原地踏步、消极被动都将导致自己被超越。随着一系列重要的企业技术的发展,2024 年很可能会成为企业在市场竞争中脱颖而出的关键一年。
今年将有三件大事发生,其各有各的风险、益处和解决方案。虽然这并不是一份详尽的清单,但其中包括了将在 2024 年以某种方式影响大多数企业的技术,而且一些企业可能已经在采用了。
- Wi-Fi 7 终于到来,它所使用的 6 GHz 频段带来了巨大的容量提升。Wi-Fi 6E 打开了这一频谱的大门,而 Wi-Fi 7 则通过多项增强功能,使其成为企业网络战略中更有价值的一部分。虽然 Wi-Fi 7 功能丰富,但最重要的是其在容量、延迟和可靠性方面的改进。
Wi-Fi 7 添加了多链路操作(MLO)功能,使接入点(AP)能够同时驱动多个频段和信道,因此同一接入点可同时提供 2.4 GHz、5 GHz和 6 GHz 的数据流,从而使容量激增,大大降低延迟。此外,MLO 还能在终端和 Wi-Fi® AP 之间提供更可靠的连接。因此,2024 年,企业将更深入地审视自身用例,并认识到曾经被认为无法通过 Wi-Fi 实现的用例终于成为可能。
此外,6.0 GHz 频段也被未授权的蜂窝网络应用所共享。这为融合网络中一些令人兴奋的应用打开了大门:
- 企业中的多接入融合网络可以将多种无线技术扁平化,不仅包括上文提到的 Wi-Fi 和专用蜂窝网络,还包括 Zigbee™ 和低功耗蓝牙®等低功耗物联网网络。
对于希望在人员和设备连接方式上实现高敏捷性的企业来说,2024 年将在如何并行驱动多个网络和协议方面取得重要进展,通过专用网络优化连接组合,满足企业的特定需求。
- 企业内部的 IT/OT 融合和物联网也将在 2024 年迎来复兴,原因如下。首先,经济形势迫使企业寻求比以往更高效的运营方式。其次,物联网设备连接方面的重要新进展(特别值得一提的是,Matter™ 和 Thread 协议正在智能家居领域掀起波澜,并在 2024 年将目光投向企业级市场)正在使零接触物联网设备连接和互操作性成为现实,并为更广泛的物联网采用消除了巨大障碍。互联设备可以为企业释放关键的效率,使企业能够将 IT (信息技术)和 OT(运营技术) 资源重新分配到利润更高的增长型优先事项上。
以上就是 2024 年对于企业的利好消息。这些技术将为未来十年或二十年的发展奠定基础,而且它们都将在同一时间成为主流技术。当然,这种增长也伴随着“成长的烦恼”,这些烦恼也可归结为横跨这些技术的三大挑战:
- 网络复杂性是伴随这些机遇而来的一项可预见的挑战。随着新网络层的增加以及网络层之间更多的集成,网络结构必然变得更加复杂且臃肿。随着 4G/5G 专网用例与 Wi-Fi用例同时增长,管理这两种技术在共享空间时产生的复杂性就成为当务之急。
- 资本支出(CapEx)和运营支出(OpEx)对于希望利用这些技术的企业都是重要因素。Wi-Fi 7 需要升级局域网基础设施,而要充分利用 IT/OT 融合和物联网的机遇,就需要特定的设备和专业知识。而在当前经济条件下,并非所有企业都能在设备和人员方面进行这样的投资。
- 业界难寻的行业专家(SME)可能成为一项限制因素,尤其是在涉及 6 GHz 和 Wi-Fi 7、专用蜂窝电话和物联网部署时。作为一种新上市的技术,Wi-Fi 7 还没有成熟的第三方支持生态系统和深厚的专业知识。即使是那些有能力负担这种专业人员配备的企业,也可能无法获得这种支持,无论价格如何。Wi-Fi 7 是支持所有这些 2024 年趋势的核心支柱,因此这一挑战可能是所有挑战中最为重大且普遍的。
这些相互关联的挑战中,每一项都像是需要攀登的陡峭山坡,但其并非无法逾越。即使企业开始感受到这些挑战,他们也有创新的解决方案可供选择。那些善于利用新技术的企业将在未来几年中处于有利地位,并最大限度地减少潜在不利因素。对于渴望充满信心地拥抱这些进步的企业,以下是其可用的三大关键资源:
- 日益经济实惠的AI复杂性管理对于复杂融合网络的高效优化、监控和管理而言至关重要。AI最近占据了很多新闻头条,但AI热潮中一个未被充分报道的方面是,在算力和效率急剧上升的同时,专用AI模型的训练成本在急剧下降。请看以下AI算力和开发成本随时间变化的图示。
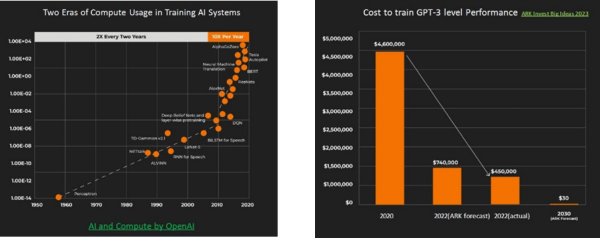
可用于训练AI系统的算力(数据由 OpenAI提供)和随着时间推移的相应成本(数据由 ARK Invest提供)示例
AI驱动的网络管理已经变得足够强大,能够以更少的 IT 参与和更精简的预算来保持融合型企业网络的平稳运行,而且根据 ARK Invest 的预测,训练专用 GPT-3 AI模型的前期成本
将骤降至几年前所需投资的 0.0065%。在企业构建更加融合、灵活和强大的网络时,AI也能帮助确保 SLA 合规性,从而消除采用AI的大部分风险。
- 物联网效率可支持 IT/OT 融合并降低成本。最新的 Matter 和 Thread 协议规范扩大了智能家居环境中受支持设备类型的数量。今年,我们可以期待 Matter 和 Thread 在企业和工业环境中取得更大进展。这些协议解决了物联网设备安全措施分散、不均衡的难题,为各种联网设备、传感器、安全和生产力应用打开了大门。从可通过更高效的管理来降低运营支出的联网恒温器和照明设备,到可改善工厂安全并提高员工人身安全的联网门锁和安全摄像头,不一而足。由于能够减少能源消耗(当然还是在经济实惠的AI管理的帮助下),并为企业带来从运输到仓储再到制造等其他方面的效率提升,物联网的部署甚至可以改善企业的可持续发展状况。
这些优势以前只能在由不同供应商的安全硬件和软件组成的分散、不可靠的生态系统中获得。经过 Matter 和 Thread 认证的设备将最终消除阻碍物联网更广泛应用的挑战和风险。
- 网络即服务(NaaS)可以减轻企业建设更智能、更融合网络的资本支出负担。NaaS是一种基于云的服务模式,以订购方式提供全套网络功能。与投资部署 Wi-Fi 7 所需的新基础设施以及与之配套的所有融合网络服务相比,企业可以将成本委托给第三方 NaaS 供应商,并将成本作为运营支出(OpEx)而非资本支出(CapEx)分期摊销。NaaS 可确保企业网络始终处于技术前沿,而无需承担设计、安装、优化、监控或管理网络的义务。NaaS 模式实现了网络带宽的敏捷可扩展性和响应性分配。
最后,对于那些受限于 IT 资源和时间,而非设计、构建、管理和支持融合网络所需的资金的企业来说,也有供应商可提供一整套“托管服务”供其选择,以满足其网络需求。
这三种解决方案的一个共同点是,它们都致力于为企业减轻与最先进的融合网络相关的复杂性。AI提供了最受欢迎的优势,即网络保障,超越了普通的监控,使精干的 IT 团队能够处理价值更高的项目。同样,为支持互操作性、安全性和简便性而构建的 Matter 和 Thread 协议所提供的定义明确的连接框架,在加速物联网应用在许多行业垂直领域的普及方面发挥着关键作用。最后,NaaS 模式可将整体体验简化为企业与网络之间简单的交钥匙关系。
2024 年的关键发展将产生远超未来一年的深远影响。如此多令人兴奋的技术进入主流,很可能为未来几十年的发展奠定基础。对于有意向接受这些技术的企业来说,如果能将AI、物联网和 NaaS 支持巧妙地结合,2024 年将成为一个非常美好的开始。
来源:业界供稿
好文章,需要你的鼓励


CES上杨元庆首谈AGI,碾压人类的叙事不会让AI更聪明
很多人担心被AI取代,陷入无意义感。按照杨元庆的思路,其实无论是模型的打造者,还是模型的使用者,都不该把AI放在人的对立面。

MIT递归语言模型:突破AI上下文限制的新方法
MIT研究团队提出递归语言模型(RLM),通过将长文本存储在外部编程环境中,让AI能够编写代码来探索和分解文本,并递归调用自身处理子任务。该方法成功处理了比传统模型大两个数量级的文本长度,在多项长文本任务上显著优于现有方法,同时保持了相当的成本效率,为AI处理超长文本提供了全新解决方案。

Gmail新增Gemini驱动AI功能,智能优先级和摘要来袭
谷歌宣布对Gmail进行重大升级,全面集成Gemini AI功能,将其转变为"个人主动式收件箱助手"。新功能包括AI收件箱视图,可按优先级自动分组邮件;"帮我快速了解"功能提供邮件活动摘要;扩展"帮我写邮件"工具至所有用户;支持复杂问题查询如"我的航班何时降落"。部分功能免费提供,高级功能需付费订阅。谷歌强调用户数据安全,邮件内容不会用于训练公共AI模型。

华为研究团队突破代码修复瓶颈,8B模型击败32B巨型对手!
华为研究团队推出SWE-Lego框架,通过混合数据集、改进监督学习和测试时扩展三大创新,让8B参数AI模型在代码自动修复任务上击败32B对手。该系统在SWE-bench Verified测试中达到42.2%成功率,加上扩展技术后提升至49.6%,证明了精巧方法设计胜过简单规模扩展的技术理念。
2024
02/06
10:38
分享
点赞

联想集团混合式AI实践获权威肯定,CES期间获评“全球科技引领企业”
CES上杨元庆首谈AGI,碾压人类的叙事不会让AI更聪明
CES 2026 | 重大更新:NVIDIA DGX Spark开启“云边端”模式
Gmail新增Gemini驱动AI功能,智能优先级和摘要来袭
研究发现商业AI模型可完整还原《哈利·波特》原著内容
Razer在2026年CES展会推出全息AI伴侣项目
CES 2026:英伟达新架构亮相,AMD发布新芯片,Razer推出AI奇异产品
通过舞蹈认识LimX Dynamics的人形机器人Oli
谷歌为Gmail搜索引入AI概览功能并推出实验性AI智能收件箱
DuRoBo Krono:搭载AI助手的智能手机尺寸电子阅读器
OpenAI推出ChatGPT Health医疗问答功能
Anthropic寻求3500亿美元估值融资100亿美元
