
Check Point揭示2022 年第四季度网络钓鱼攻击最常被冒充的品牌
2023 年 1 月,网络安全解决方案提供商 Check Point® 软件技术有限公司(纳斯达克股票代码:CHKP)的威胁情报部门 Check Point Research (CPR) 发布了其《2022 年第四季度品牌网络钓鱼报告》。该报告重点介绍了去年 10 月、11 月和 12 月网络犯罪分子在企图窃取个人信息或支付凭证时最常冒充的品牌。
在 2022 年第四季度,雅虎是网络钓鱼攻击中最常被冒充的品牌,排名上升了 23 位,在所有网络钓鱼攻击中占比 20%。Check Point Research 发现,在网络犯罪分子散播的电子邮件中,主题行通常显示收件人赢得了“大奖促销”或“奖励中心”等发件人发放的奖品或奖金。这些电子邮件会告知攻击目标,他们赢得了雅虎提供的奖金,价值数十万美元,要求收件人提供其个人信息和银行信息,并声称会将中奖奖金转入该账户。这些电子邮件还会警告攻击目标,由于涉及法律问题,因此不得将中奖消息告知他人。
总体而言,在 2022 年最后一个季度,科技行业是品牌网络钓鱼攻击最常冒充的行业,其次是运输和社交网络行业。DHL 位列第二,在所有品牌网络钓鱼攻击中占比 16%;微软位居第三,占比 11%。本季度,LinkedIn 也重返榜单,排名第五,占比 5.7%。DHL 之所以成为热门的冒充目标,很可能与年末网购季有关,黑客大量利用该品牌生成“虚假”发货通知。
Check Point 软件技术公司数据事业部经理 Omer Dembinsky 表示:“我们发现,黑客正试图通过提供奖品和巨额奖金来引诱攻击目标。请谨记,如果遇到“天上掉馅饼”的事情,那很可能就是陷阱。请勿点击可疑链接或附件,并务必检查跳转页面的 URL,以防范品牌网络钓鱼攻击。查找拼写错误,切勿主动提供不必要的信息。”
最常被冒充的十大品牌
以下是按照在网络钓鱼攻击中的总出现率进行排名的最常被冒充的品牌:
- 雅虎 (20%)
- DHL (16%)
- Microsoft (11%)
- Google (5.8%)
- LinkedIn (5.7%)
- WeTransfer (5.3%)
- Netflix (4.4%)
- FedEx (2.5%)
- 汇丰银行 (2.3%)
- WhatsApp (2.2%)
Instagram 网络钓鱼电子邮件 — 帐户窃取示例
CPR 发现了一起恶意的网络钓鱼电子邮件攻击活动,其发件人为“badge@mail-ig[.]com”。这封电子邮件的主题是“蓝色徽章表单”,邮件内容试图说服受害者点击一个恶意链接,声称受害者的 Instagram 帐户已通过 Facebook 团队(Instagram 品牌的所有者)的审查,有资格获得蓝色徽章。
图 1.主题为“蓝色徽章表单”的恶意电子邮件
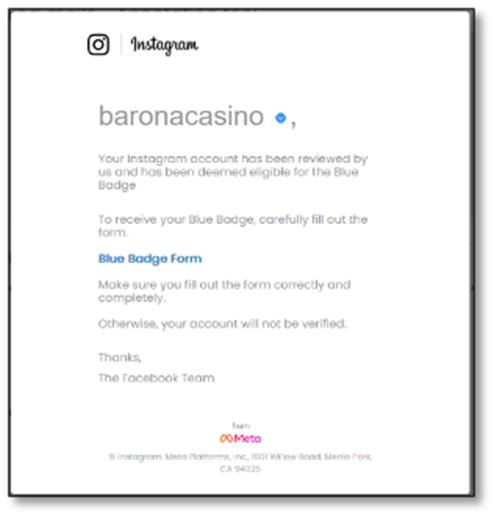
图 2:欺诈性登录页面 https://www[.]verifiedbadgecenters[.]xyz/contact/

Microsoft Teams 网络钓鱼电子邮件 — 帐户窃取示例
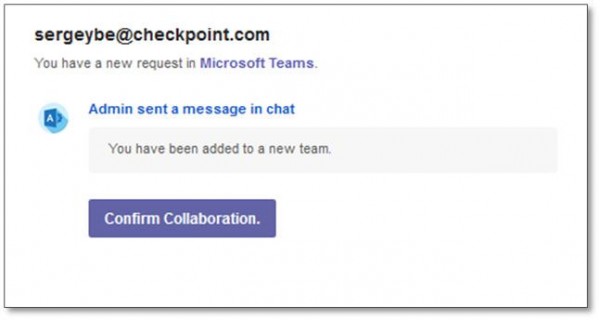
在这封网络钓鱼电子邮件中,Check Point Research 发现攻击者试图窃取用户的 Microsoft 帐户信息。该电子邮件以伪造的发件人名称“Teams”从“teamsalert_Y3NkIGpoY2pjc3dzandpM3l1ODMzM3Nuc2tlY25taXc@gmx[.]com[.]my”地址发出,主题为“您已被添加到新团队”。
攻击者试图引诱受害者点击恶意链接,声称他们已被添加到应用中的新团队。选择确认加入将转至恶意网站“https://u31315517[.]ct[.]sendgrid[.]net/ls/click”(已失效)。
图 3:主题为“您已被添加到新团队”的恶意电子邮件
来源:业界供稿
好文章,需要你的鼓励


对话SUSE亚太区CTO Vishal Ghariwala:用开源拆掉企业AI的“无形围墙”
在他看来,企业对AI的恐惧源自未知,而破解未知的钥匙,就藏在“AI平台+开源”这个看似简单的公式里。

AI模型“性格“大揭秘:斯坦福和魁北克团队首创“超新星事件“测试法,发现人工智能也有独特人格
斯坦福和魁北克研究团队首创"超新星事件数据集",通过让AI分析历史事件和科学发现来测试其"性格"。研究发现不同AI模型确实表现出独特而稳定的思维偏好:有些注重成就结果,有些关注情感关系,有些偏向综合分析。这项突破性研究为AI评估开辟了新方向,对改善人机协作和AI工具选择具有重要意义。

Pure推出企业数据云:存储管理策略导向新突破
Pure Storage发布企业数据云(EDC),整合其现有产品组合,提供增强的数据存储可见性和基于策略的简化管理。EDC集成了Purity存储操作系统、Fusion资源管理、Pure1舰队管理和Evergreen消费模式等架构元素,提供类云存储管理环境。该方案支持声明式策略驱动管理,让客户专注业务成果而非基础设施管理。同时发布高性能闪存阵列和300TB直接闪存模块,并与Rubrik合作提供网络安全防护能力。

代码验证能否做到既快又准?威斯康星大学破解大型语言模型编程任务的速度与精度平衡难题
威斯康星大学研究团队提出"生成-筛选-排序"策略,通过结合快速筛选器和智能奖励模型,在AI代码验证中实现了11.65倍速度提升,准确率仅下降8.33%。该方法先用弱验证器移除明显错误代码,再用神经网络模型精确排序,有效解决了传统方法在速度与准确性之间的两难选择,为实用化AI编程助手铺平了道路。
2023
01/31
12:04
分享
点赞

对话SUSE亚太区CTO Vishal Ghariwala:用开源拆掉企业AI的“无形围墙”
通义APP全面升级翻译能力,打造最强翻译综合体
Pure推出企业数据云:存储管理策略导向新突破
LLM聊天机器人学会了察言观色:希伯来大学突破性研究让AI懂得何时说话
推理模型存在崩溃缺陷?Open Philanthropy研究人员提出AI推理能力评估的改进方法
盖洛普新报告:AI文化准备需要全新思维模式
微软测试物理PC到云PC故障转移服务应对设备故障
智能体AI重塑企业安全与可观测性的未来发展
企业高管对开源AI模型持谨慎态度偏爱专有方案
Threads正在测试剧透隐藏功能,扎克伯格透露
1Password携手AWS共推企业AI与云环境安全防护
Tinder推出双人约会功能,用户可与朋友配对聊天
Check Point:以AI技术赋能云端交付平台化安全解决方案
Check Point 推出全新 SaaS 威胁防御解决方案
Check Point:2024年,企业应积极推进行云安全变革
Check Point推出 ThreatCloud Graph:从多维视角评估网络安全态势
Check Point:网络安全发展历史大事记
Check Point+七云网络 强强共建SD-WAN安全
沃尔玛成为 2023 年第三季度网络钓鱼诈骗中最常被冒充的品牌
服务出海 Check Point全面防御内外威胁
Check Point 软件技术公司通过全新安全托管功能增强了 Infinity 全球服务
Check Point Software 第三季度业绩超预期
