
Fortinet 2023上半年全球威胁态势研究报告:勒索软件检测成下降趋势,针对性攻击持续升温
近日,专注于推动网络与安全融合的全球网络安全企业Fortinet®(NASDAQ:FTNT),发布《2023上半年全球威胁态势研究报告》。报告显示,2023 年上半年勒索软件检出数量继续下降、高级持续性威胁(APT)团体活跃度显著增加以及攻击者使用的 MITRE ATT&CK 技术呈现飞速转变等威胁发展趋势。
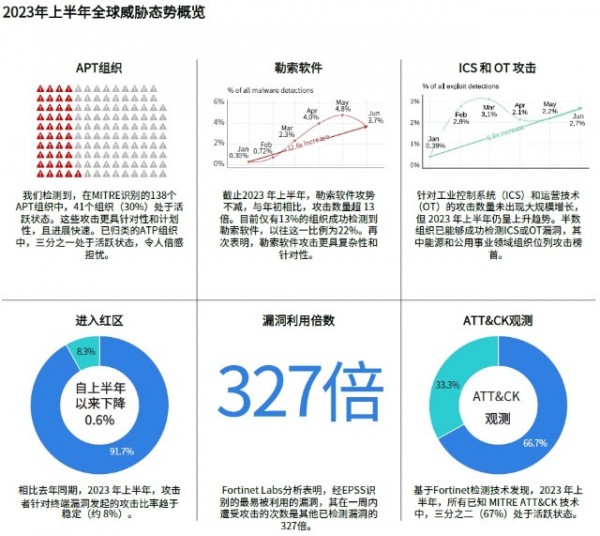
由于恶意行为者所用战术和技术的日益复杂以及针对性攻击的不断升级,目前组织持续处于被动局面。《2023 上半年全球威胁态势研究报告》对威胁态势进行了持续跟踪剖析,有助于提供高价值情报,并作为潜在威胁活动的早期预警系统,帮助安全管理者制定更为明智的安全策略并明确漏洞修复优先级。
以下是本次报告的四大关键发现:
关键发现一、变体数量与检出量的冰火两重天
报告显示,近年来勒索软件变体数量大幅飙升,这一趋势的发展主要源自勒索软件即服务(RaaS)模式的大肆兴起。然而,与这一趋势相反的是2023 上半年仅有 13% 的组织成功检测到勒索软件,而五年前这一比例为22%。
Fortinet FortiGuard 全球威胁研究与响应实验室(FortiGuard Labs)对过去几年间的威胁发展趋势进行了总结发现,这种变体数量与检出量冰火两重天的趋势,是由于攻击者所用战术和技术的日益复杂以及提高单次攻击投资回报率(ROI)的强烈意图,也就是勒索软件和其他攻击变得更具针对性。换言之,勒索软件攻击变得“轻易不出手,出手即万事俱备、志在必得”。
关键发现二、高评分漏洞7日危险期威胁陡增
FortiGuard Labs 在本次报告中对近六年漏洞利用历史数据进行了分析,这些数据涉及11,000多个已公开披露的CVE漏洞。分析发现漏洞利用预测评分系统(EPSS) 评分最高(前 1%高危漏洞)的通用漏洞披露(CVE)在7 天内被利用的可能性是其他漏洞的 327 倍。
关键发现三、红区结合有效的补丁管理策略
FortiGuard Labs 基于 EPSS 评分中被在野利用的漏洞分析结果定义红区,在量化终端上遭受主动攻击的可利用漏洞比例的同时,助力首席信息安全官确定漏洞修复优先级。报告显示,已发现、现存和被利用的漏洞数量持续波动,在修复优先级指导下组织实施有效的补丁管理策略显著减少了红区面积。
关键发现四、近三分之一 APT 组织处于活跃状态
本次报告,FortiGuard Labs首次追踪了当前趋势背后威胁参与者的数量。研究表明,2023 年上半年,MITRE 追踪的 138 个网络威胁组织中有 41 个(30%)处于活跃状态。基于恶意软件检测结果显示,其中Turla、StrongPity、Winnti、OceanLotus和WildNeutron等组织是目前最活跃的黑客团体。APT组织的活动演变和数量将成为未来报告中值得期待的焦点。
全方位合力打击网络犯罪
作为企业级网络安全与网络创新解决方案领导者,Fortinet持续保护全球各类企业、服务提供商和政府组织,用户基数超 50 万。值得一提的是,Fortinet持续开发应用于网络安全用例的人工智能(AI)技术,并将其纳入FortiGuard Labs实验室和各类产品组合中,这一创新举措可有效加速对已知和未知威胁的预防、检测和响应。
FortiGuard AI 驱动的安全服务可跨网络和云基础架构的终端和应用程序部署的安全控制组件加以利用。基于 AI 引擎和云分析(包括 EDR、NDR 等)的专用检测和响应技术也可作为此类控制组件的集成扩展功能进行部署。此外,Fortinet 还提供XDR、SIEM、SOAR、DRPS 等集中式响应工具,利用不同 AI 技术、自动化和编排功能加速威胁修复,从而显著挫败整个攻击面和网络攻击杀伤链上的网络犯罪活动。
好文章,需要你的鼓励



明尼苏达大学最新研究颠覆认知:训练AI大模型,只需动其中一层就够了?
这项来自明尼苏达大学等机构的研究发现,大语言模型在强化学习后训练中,只需训练中间少数几层即可匹配甚至超越全参数训练效果,且这一规律跨模型、跨任务高度稳定,为更高效的AI训练策略提供了新思路。


台湾大学与NVIDIA揭秘:你的声音正在悄悄改变AI对你的判断
本文介绍VIBE框架,一套通过开放式任务评估大型音频语言模型声音诱发偏见的系统,测试12个模型后发现每个模型均存在显著性别或口音偏见。
2023
09/27
18:10
分享
点赞

机器人管家系统上线!傅利叶携多款康养陪伴新品方案亮相WAIC 2026
赛那德“ 自主作业机器人天团” 登陆 WAIC:iLoabot-X+模型双升级,秀出具身场景落地硬实力
西门子Eigen工程智能体中国首发首展,荣获2026 WAIC SAIL之星奖
NVIDIA Cosmos 推动物理 AI 前沿发展
PPIO亮相WAIC 2026:发布智能模型网关,打造面向Agent时代的智能Token工厂
端侧感知、私有闭环、量子协同, NVIDIA全栈异构计算范式“接管”实体产业底座
边缘智算筑基、全栈软硬协同,研华科技将AI带进产业闭环
千问AI眼镜将升级为智能体眼镜:能灵活调用Skill和Agent,能全天候感知
对话Moonix郭于晨:先让用户戴上“眼镜”,再让“AI”记录世界
亮相WAIC 2026,临床实证赋能康养升级 无芯科技定义AI疗愈新范式
生态覆盖持续扩散,一文看懂各行业企业鸿蒙化转型进度
WAIC亮出集群协作真功夫,优艾智合领跑工业具身智能规模化
营收稳健 利润攀升!Fortinet发布2024年第四季度及全年财报
三大驱动,Fortinet打造全球安全网络防线
Fortinet 发布2024年第三季度财报
2024 Fortinet OT工业安全高峰论坛成功举办 开启OT安全平台时代
OT安全零死角!Fortinet OT安全平台再升级
持续扩张网安版图 Fortinet宣布完成两项重大收购!
Fortinet斩获2024年Gartner单一供应商SASE魔力象限“挑战者”
Fortinet:98%企业竟存N日漏洞超5年,新漏洞利用攻击时长极速缩短
加速平台化战略,Fortinet打造全方位网络安全
层层防护企业网络安全 Fortinet Accelerate 2024中国区巡展北京站圆满落幕
