
Fortinet 全球零信任态势报告:超半数企业组织在搭建零信任架构时面临挑战
在网络安全领域,零信任(zero-trust)安全概念早已风靡多年,多数网络安全权威专家对零信任安全理念表示高度认同。尽管一些组织已经构建了某种形式的零信任安全体系愿景,遗憾的是,这些愿景或规划并不足以支撑相关的解决方案付诸实践。不仅如此,甚至关于如何定义零信任战略,用户也普遍存在困惑。零信任安全的未来已来,组织应当对其有正确认知并尽快付诸实施。
“知其然而不知其所以然”-零信任战略认知不足
据Fortinet最新发布的全球零信任态势报告显示,对于零信任战略,77%的受访者表示他们对零信任有所了解,75%的受访者则表示他们熟悉零信任网络访问(ZTNA)概念。超过 80% 的受访者表示,他们已经构建或正在构建零信任和/或零信任网络访问(ZTNA)战略。然而,依然有超 50% 的受访者认为,他们尚不具备实施零信任核心功能的组网能力。近 60% 的受访者表示,他们无法持续对用户和设备进行身份验证,还有54% 的受访者表示难以在身份验证后对用户和设备进行监控和管理。
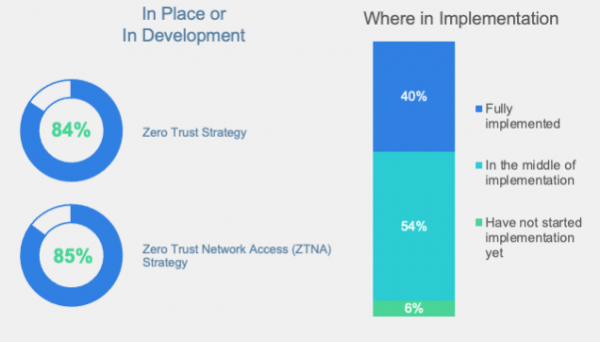
受访者普遍对于零信任缺乏全面的认知,由于认知不足造成的安全能力短板情况严峻,令人担忧。这些缺失的能力恰是保障零信任战略顺利实施的关键所在。“零信任访问(Zero Trust Access)”和“零信任网络访问(Zero Trust Network Access,)”这两个术语看似相同却差别甚远,ZTNA可以说是ZTA的一个子集,用于控制应用的接入,无论应用的用户或者应用本身在哪。
“力不从心”-零信任实施面临挑战
要实现零信任,首要任务是最大限度地减少漏洞和入侵对网络安全带来的负面影响,其次是确保远程访问安全和保障业务或任务的顺畅运行,当然提升用户体验和随时随地安全防护的灵活保障同样不容忽视。总体而言,整个数字攻击面的安全防护是部署零信任架构的突出优势,其次便是获得替代VPN的更佳远程办公体验。

对于大部分组织来说,零信任安全解决方案必须能集成现有基础设施,覆盖云端和本地部署网络环境,并且保持应用层面的安全状态。然而,调查显示超80%的受访者提出,在一个边缘不断扩展的网络中实施零信任战略极具挑战,尤其众多组织在对用户和设备进行持续身份验证方面力不从心。而对于一些尚未制定或构建零信任战略的组织而言,他们所面临的阻碍还包括缺乏技术资源的有力支撑。
未来已来- Fortinet高效的零信任解决方案
调查显示,当组织面临这些挑战时,绝大部分情况源自于在构建零信任战略的进程中,缺少优质提供商为组织提供全面、完善的解决方案。想要形成一套行之有效的安全解决方案,需要具备网络安全网格平台构建能力的优质提供商,为包括端点、云和本地部署在内所有基础设施配备完整的零信任基本要素,否则该方案仅仅是一套局部且非集成的解决方案,缺乏广泛的可视性。

高效的零信任解决方案作为一个全面集成系统协同工作所具备的基本要素,能够抵御组织所面临的各种安全防护和管理漏洞。例如,全面集成零信任策略、端点防护以及网络安全解决方案的Fortinet Security Fabric 安全架构,可在跨分布式网络环境下自动追踪用户,输出高质量威胁情报信息,构建积极主动的安全防御体系。这种一体化方法可筑起主动防御、全面整合及上下文感知的安全防护壁垒,无论用户身处何处、使用何种设备访问网络或访问何种资源,都能轻松实现自适应且应对自如。
好文章,需要你的鼓励


首个AI勒索软件攻击事件:幕后仍有人类参与
云安全公司Sysdig记录了首个"代理式勒索软件"案例——JadePuffer行动。AI代理自主完成入侵服务器、窃取凭证、加密文件并生成勒索信等全流程操作,速度惊人。然而,该攻击并非完全无人介入:人类仍负责选定目标、部署基础设施并提供初始访问凭证。研究人员暂未确认驱动该代理的具体模型,但指出随着运行成本降低,类似攻击规模可能快速扩大。

阿里巴巴AMAP团队的AI提速新招:让大模型推理快4.2倍,秘诀是“动态换挡“
阿里巴巴AMAP团队提出BlockPilot,通过自适应预测每个输入的最优推测解码块大小,在Qwen3-4B上实现4.20倍无损推理加速,比现有最优方法提升约10%。

英国机器人公司Humanoid推出强化学习系统,机器人操控可靠性提升至99.9%
英国机器人与AI公司Humanoid发布KinetIQ Ascend强化学习系统,目标是以人类速度甚至更快达到99.9%的操作可靠性。该系统通过试错学习,在多项工业任务中表现出色:在机器送料任务中吞吐量提升42%,拣货递物任务成功率从80%升至98%,双臂搬运任务成功率达99%,且所有成果仅需数天训练即可实现。该系统还展示出类似大语言模型的扩展规律,训练时间越长性能越稳定提升。

上交大与字节跳动联手:不用Docker也能训练出顶级代码AI,这项技术彻底打破了“必须有测试环境“的枷锁
上交大与字节跳动提出无环境代码AI验证器Dockerless,无需Docker测试环境即可判断代码修复正确性,训练性能接近传统环境化方法。
2022
01/26
11:51
分享
点赞

英国机器人公司Humanoid推出强化学习系统,机器人操控可靠性提升至99.9%
Waabi AI驾驶系统无需重新训练即可迁移至沃尔沃自动驾驶卡车
Apptronik携手谷歌DeepMind开设机器人训练园区,加速人形机器人商用部署
一个自我进化的开源代码模型突然火了,单张显卡实测效果真不错
比亚迪旗舰电动轿车海豹08上市30小时锁单超6.5万辆
特斯拉司机高速公路上熟睡,驾驶员监控系统为何失效?
AI助手争夺战:苹果能成为最终赢家吗?
NHS App将引入AI分诊工具,助力缩短患者等待时间
Station F加速器助力欧洲AI创业公司崛起
橡树岭国家实验室与克利夫兰诊所联合模拟聚变反应堆材料化学
Even Realities完成1.5亿美元融资,估值达10亿美元
数据中心会造成空气污染吗?关键在于电力来源
营收稳健 利润攀升!Fortinet发布2024年第四季度及全年财报
三大驱动,Fortinet打造全球安全网络防线
Fortinet 发布2024年第三季度财报
2024 Fortinet OT工业安全高峰论坛成功举办 开启OT安全平台时代
OT安全零死角!Fortinet OT安全平台再升级
持续扩张网安版图 Fortinet宣布完成两项重大收购!
Fortinet斩获2024年Gartner单一供应商SASE魔力象限“挑战者”
Fortinet:98%企业竟存N日漏洞超5年,新漏洞利用攻击时长极速缩短
重塑安全防护体系 Akamai推出零信任平台Akamai Guardicore Platform
加速平台化战略,Fortinet打造全方位网络安全
