
双十一遇到的困惑,西方小伙伴表示有同感
刚刚过去的周末,周围几乎所有的亲朋好友以及同事们都或多或少的参与了一下这个年度购物狂欢节。甚至我在北美的同事也会惊呼现在的“Single’s Day”已经不亚于“Black Friday”和“Cyber Monday”的影响力。而从技术的角度讲,这样集中且高密度的客户访问流量,对任何一家电商的基础设施来说都是巨大的挑战。我的一位负责技术营销的同事Golan Shem-Tov跟我分享了一些他的有趣经历。
Golan回忆道:其实,在几年前,当我刚开始接触应用性能管理(APM)的时候,我就有幸亲身经历了一次类似网络购物狂潮的事件。随着客户流量的激增,当我走回自己办公桌的时候,看到运维团队的一位同事正面露难色的看着他的电脑屏幕,因为屏幕上的图标颜色由绿变成了橙色,有的甚至变成了红色。他看着我,然后说道:‘看着就像圣诞夜的彩灯,一个漫漫长夜就要来啦’。
今天,当我看着我们为年底购物季所准备的合成监测系统正在变换颜色时,我不禁想到了过去的情形。我们使用的这些合成监测系统很简单,监测的这些网站也是我的朋友和家人经常去购物的网站。由购物高峰所带来的结果也都很值得关注。
这里有几个关于在某个“网购星期一”网络可用性和最大响应时间的例子,非常有趣。这里隐去网站的名称以便于通用业务描述:
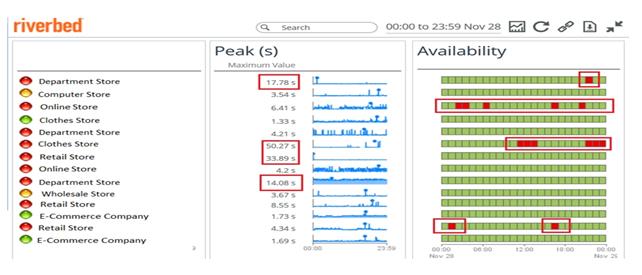
从上图,我们发现了一些有趣的问题,比如某个店铺的站点经常出现超时故障:
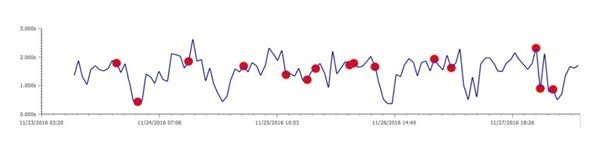
另一家百货店的平均响应时间超长,请求超时,响应时间高达54秒:

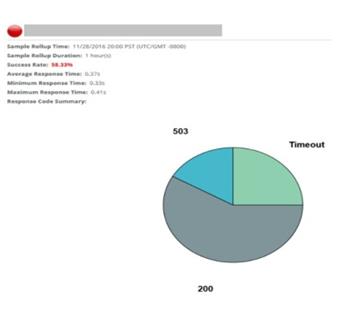
还有一家服装店存在HTTP 503错误和超时现象:
我相信很多人都为此长时间忙碌过,甚至是熬夜加班,而我们每年都会看到或听到类似的新闻,这种现象在过去几年一直都有,但是不是就真的没办法解决?
答案是否定的,根据目前业界普遍达成的共识,经过市场验证的综合应用性能监测系统应该具备以下能力:
- 可对访问Web站点的真实用户响应时间与可用性进行监测并报警
- 使用合成交易对响应时间与可用性进行监测和报警,从而确保网络和应用一切正常
- 通过监测应用交易及系统处理应用交易的方式找出问题根源
- 监测应用运行的基础设施
- 找出发现中断的根源,更快解决问题
时代已经改变,越来越多的电商企业需要找到既可以探测并预警问题、又可以帮助企业快速诊断问题,并缩短解决问题时间且减少财务损失的综合解决方案。为了确保下一个“双11”网络交易平台的正常运营并超越竞争对手,现在就开始行动吧!
好文章,需要你的鼓励



腾讯混元视觉团队打造“图像翻译官“:让AI用离散数字读懂每一张照片
腾讯等机构提出ViQ框架,通过两阶段渐进量化训练,让离散视觉编码在多模态理解和图像重建上同时追平连续特征编码器,训练速度最高提升70%。

Chrome、Edge、Firefox 浏览器 AI 功能横评,我最终选了这款
作者对Chrome、Edge和Firefox三款主流浏览器的内置AI功能进行了实测对比。Chrome依托Gemini提供搜索摘要与提示词保存功能;Edge集成Copilot,可针对网页、PDF及多标签页进行问答;Firefox则支持多款AI聊天机器人,并提供更强的隐私保护。综合体验后,作者最终选择Edge作为AI辅助浏览的首选,但仍以Firefox作为默认浏览器。

香港科技大学联手华为研究院:AI绘图训练速度提升2.78倍,秘诀藏在“概率分工“里
香港科技大学与华为联合提出LISA训练方法,通过让副网络对齐"似然分数",将ControlNet等图像生成模型的训练收敛速度提升逾2.78倍,同时改善图像质量与条件控制精度。
2017
11/14
10:39
分享
点赞

Chrome、Edge、Firefox 浏览器 AI 功能横评,我最终选了这款
Firefly宇航公司首次在月球轨道运行NVIDIA Jetson平台
超越数据驱动美学:计算与审美的跨世纪探索
韩国携手三星和SK海力士启动5840亿美元芯片制造计划
Gemini 个性化 AI 图像生成功能现向美国用户免费开放
HP与OpenAI达成合作,共同部署企业级AI智能体平台
Windows 10 用户最长可免费获得安全更新至 2027 年
Raise Us:AI巨头联合出资5亿美元帮助劳动者应对AI时代冲击
MIT首届音乐科技研究展:AI与音乐共创的跨学科探索
特斯拉"完全自动驾驶"集体诉讼引用Electrek报道作为证据
福特3万美元电动皮卡再度现身测试路段
美国最大变压器工厂扩建,剑指AI数据中心用电需求
