
CTO下午茶:化繁为简,面面俱到
ZD至顶网网络频道 03月07日 综合消息:经常接触不同行业的 CTO,我发现谈到 IT 系统,大家关注的方向往往差异很大。有时,即使是处在同一行业,也会因企业规模的不同而各有侧重。
例如,制造行业较多关注的是整体 IT 的成本,一直到未来 3~5 年内的 TCO(Total Cost of Ownership,即整体拥有成本);医疗行业,比如医院,更在意整体应用系统的稳定性、可管理性和安全性,毕竟医院的很多临床业务应用直接关系到患者的身心健康甚至生命安危;金融行业,比如银行、证券,则更聚焦在 IT 系统的安全性、性能表现、以及未来随业务扩展的平滑和敏捷性,因为对他们而言,安全、性能、速度意味着更好的服务体验。
然而,万变不离其宗。不改变 IT 架构,这些需求会越来越难以满足。
这并非夸大其辞,一位制药行业的 CTO 曾对我说:5年前,公司的业务规模只有 200 万销售额,1台服务器挂个磁盘阵列就轻松解决业务需求;现在,公司年销售额猛增至 30 多个亿,业务部门信息化应用的需求也越来越多,服务器和存储的数量快速增加,IT 架构扩展、运维管理的瓶颈越来越突出,IT 投资也逐年攀升!这位 CTO 坦言,这些问题已困扰他多时。
当企业规模开始迅速扩大,旧有的 “膏药式” IT 采购和部署方式的潜在弊端会被骤然放大——高昂的采购和维护成本、充满风险的扩展过程、不同品牌厂家带来的兼容性问题,甚至出现问题后的互相推诿……
有没有一项能化繁为简、面面俱到的强大技术呢?
有!超融合架构,在国外被称为 Hyperconverged infrastructure。从这个技术诞生之日起,它就备受 CTO 们的关注。
IDC 最新的一项全球范围调查数据[1] 表明,在 2014~2019 年间,超融合架构以近 70% 的年复合增长率,成为行业 CTO 们的战略投资首选。
超融合架构的最大特点就是将传统 IT 架构中彼此隔离的网络、服务器和存储系统基于虚拟化平台进行融合。不过,这种融合的能力不同厂商之间也是百家争鸣,各显神通。
然而从本质上讲,基本可以概括为组装型、开源型和商用型三类。
组装型:由用户自行采购设备,采购成本低,但达到最佳实践需要用户凭经验摸索,时间成本较高,最大的问题是兼容性隐患大、可靠性差、故障率高。
开源型:用户主要选择开源软件降低成本,主要的陷阱是软件的碎片化,一旦开源系统服务外包的核心人员离职,后续运维与维护就会面临很大的挑战。
商用型:用户选择信赖的厂商,采用商用软件+商用硬件,主流商用公司之间的互认证,保障了兼容性和可靠性。
而作为商用型的领头羊,思科希望达到更全面、更深入的融合,并非简单集成——思科 HyperFlex 超融合架构,目前也是业界唯一将网络、计算和存储系统、虚拟化软件进行深度融合的最完整超融合架构。
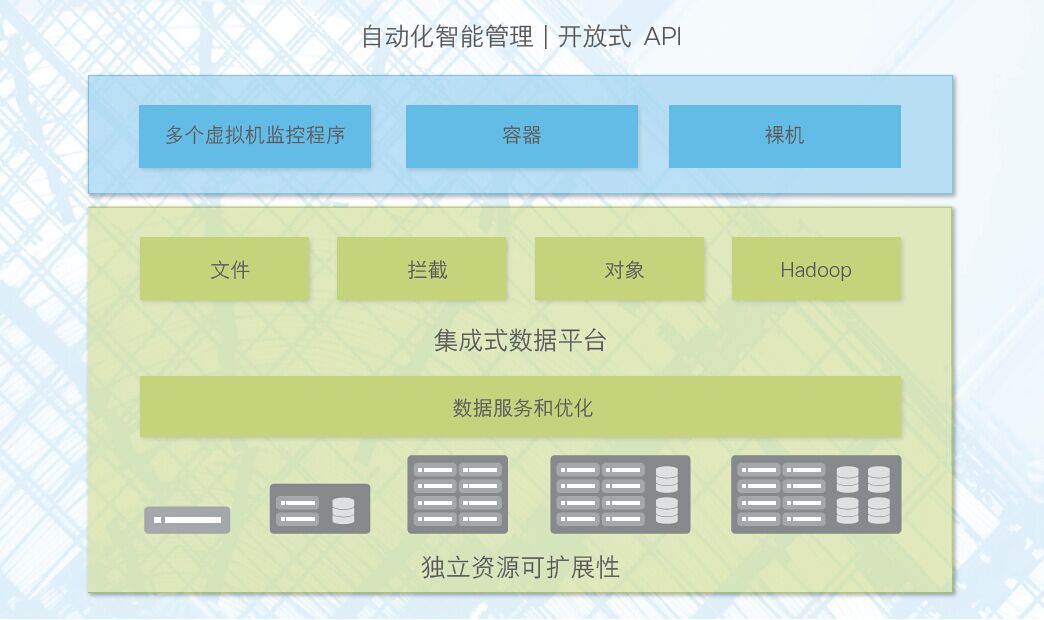
深度融合的特点,使思科 HyperFlex 超融合架构不仅具备强大的数据优化能力,而且支持统一管理,可面向更广泛的工作负载,从而实现管理的简化、扩展的平滑性和整体成本的收缩。
江苏利诚纺织集团近期建设的第二代 IT 系统,通过引入思科 HyperFlex 超融合架构,采购成本降低了约 15%,服务和管理成本降低了 30% 左右。不仅大幅降低了 TCO,提高了 ROI,IT 也更加高效,更能聚焦于业务创新。

记得金庸的《笑傲江湖》中,风清扬传授给令狐冲的 “独孤九剑”,把破解普天下所有兵器和拳脚功夫的招数,简化浓缩成九式。这和我们今天聊的思科 HyperFlex 超融合架构,颇有异曲同工之妙。
化繁为简,也正是驱动科技发展的有趣动力之一。

好文章,需要你的鼓励


OpenAI在版权诉讼中疑因隐瞒证据遭遇重大危机
OpenAI在与多家新闻机构的版权诉讼中陷入困境。以《纽约时报》为首的原告指控OpenAI在长达两年时间里向法庭撒谎,刻意隐瞒其已对ChatGPT日志进行大规模搜索的事实。据悉,OpenAI实际上已拥有包含1000万和7800万条记录的日志样本,并曾用于研究版权内容过滤器,却对外声称无法进行此类搜索。原告据此提出制裁动议,要求法院追责。OpenAI则否认相关指控,坚称其立场基于合理使用原则。

当AI学会“挑剔“:斯坦福与伯克利联手打造的智能验证框架,让AI自己检验自己的答案
斯坦福与UC伯克利提出LLM-as-a-Verifier框架,通过提取AI模型内部概率分布生成连续评分,在代码、机器人、医疗领域均达到最优性能,且无需额外训练。

外科医生远程操控人形机器人,完成全球首例活猪手术
美国加州大学圣地亚哥分校研究团队在《自然》期刊发表研究成果:外科医生通过远程操控宇树G1仿人机器人,成功完成两例活体猪胆囊切除手术,创下全球首例。与造价数十至数百万美元的达芬奇手术机器人相比,仿人机器人成本更低、体积更小,未来有望部署于农村、战地乃至太空等资源匮乏的医疗场景。但目前仍存在需频繁重新校准、机械臂活动范围受限等挑战。

字节跳动Seed团队发现:AI智能体学习新任务的速度,正以每三个月翻倍的惊人节奏增长
字节跳动Seed团队发现AI智能体在真实环境中学习的进步曲线精确遵循对数S形规律,R?达0.998,且前沿模型的学习速度每三个月翻倍。
2017
03/07
11:43
分享
点赞

OpenAI在版权诉讼中疑因隐瞒证据遭遇重大危机
外科医生远程操控人形机器人,完成全球首例活猪手术
OpenAI发布ChatGPT Work:AI助手可连续工作数小时
欧盟向Meta施压:关闭自动播放和无限滚动,否则面临巨额罚款
世界模型的潜力与局限:它真的能模拟一切吗?
苹果起诉OpenAI:前员工利用系统漏洞窃取商业机密
如何利用开源AI智能体实现工作流程自动化
Cloudzy 云服务评测:VPS 性能与体验全面解析
这款PCIe插卡内置38核至强处理器与64GB内存,堪称完整服务器
是否该为企业招募数字员工?AI 智能体团队搭建全指南
AI赋能自主机器人:从工厂走向家庭的未来图景
数据中心能源需求威胁特朗普"美国制造"计划
