
华为Wi-Fi网络助力土耳其首条无人驾驶地铁线
土耳其伊斯坦布尔的第一条地铁修建于1875年,是世界上最古老的地铁线路之一。为了缓解这座1000万人口特大城市的交通拥塞状况,伊斯坦布尔地铁三期工程已经完工,总长度达到110.5千米;其中UUC线路将是土耳其第一个无人驾驶的地铁线,自动化程度非常高。同时为了确保民众的出行安全及应对突发事件,列车在高速运行过程中,监控系统大量数据需要实时回传到地面监控中心,这就对网络可靠性和传输能力提出了更高的要求。列车上的数据实时回传地面,对Wi-Fi网络方案来说面临如下诉求:
高带宽:为了满足地铁上全高清摄像需求,每辆列车至少需要140M带宽,而且需要应对视频流量突发情况,极端情况下需要满足视频流量200M,Wi-Fi网络需要承载高带宽高清监控视频。
稳定性:列车在高速移动中,车载AP与轨旁AP之间需要频繁的快速切换,如果切换性能不满足要求,会频繁出现丢包率高、系统掉线等问题,导致列车上的数据无法正常回传到地面。所以要保证列车高速运行状态下的视频清晰流畅。
可靠性:列车在高速移动中,会带来强烈的震动,大风也会带来很多灰尘,隧道墙体经常会有水汽凝结,这些恶劣的外部环境对设备可靠性都提出了较高的要求。
针对以上挑战,华为应用WLAN轨道交通解决方案,满足土耳其地铁Wi-Fi网络对高带宽,可靠性,和稳定性的要求,保证数据实时回传地面,为土耳其UUC地铁打造安全出行的屏障。
- 高性能产品,满足车载和室外极端环境安装部署要求
华为WLAN轨道交通解决方案采用定制化的轨道交通无线接入点设备。车载AP满足防震和防火阻燃等标准,轨旁AP采用业界最高等级的防尘防水标准,细小尘埃无法进入,也不惧雨淋,满足极端环境下安装部署要求,有效避免恶劣天气和环境影响。此外,华为轨旁AP采用全金属外壳设计,内置天馈口、网口、交流供电口防雷器,省去了购置防雷器的成本,每个室外AP可以节省100美元投资,也避免了多个无源器件导致的故障问题,提高稳定性与可靠性。
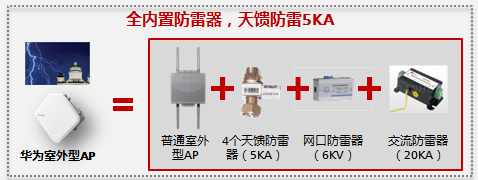
图1:华为室外AP全内置防雷器
- 保证链路带宽,双5G技术保证回传可靠性
华为轨旁及车载AP使用5G频段用作数据回传,可有效减少干扰。同时,链路带宽在列车静止时达到1.3Gbps,在时速80km/h的情况下能达到300Mbps,提供充足的链路带宽;轨旁AP8130DN采用的是业界首款支持双5G技术的款型,一台AP可以实现双频5GHz异频段点覆盖,不仅解决了车地链路的可靠性问题,还可以采用负载均衡技术,同时部署车头尾两组设备,双链路备份进一步提高车地回传的可靠性。

图2车载AP和轨旁AP双链路备份
- 专利技术,链路快速切换,业务无感知
华为WLAN轨道交通解决方案采用专利多Link预链接技术,支持一个车载AP同时与多个轨旁AP建立链接,在信号强度满足切换条件时直接无缝切换;并且应用链路切换抑制专利算法,能够有效保证链路的稳定性,避免频繁切换带来吞吐性能的下降。在80km/h速度下,链路切换时间不超过50ms,保证链路切换时业务不受影响。
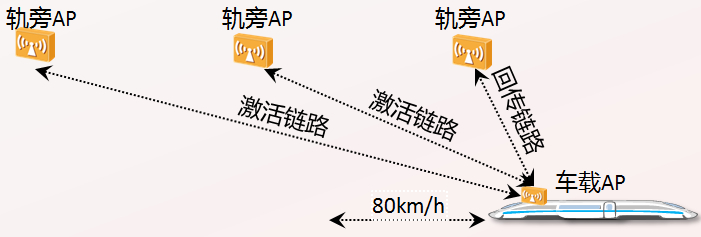
图3车载AP和轨旁AP链路无缝切换
- 天线定制化,抗风能力强,保证信号精准覆盖
轨旁天线采用30度小角度定向天线,定向性更好,抗干扰能力强,同时采用抗风设计,形状截面小,车辆快速移动产生大风时不易产生移动。列车上安装空间有限,传统抱杆或挂墙安装容易因为地铁行驶中产生的震动导致位置发生偏移,华为采用定制化的小型板状天线,针对车载特殊环境,定制化安装件来固定天线,保证天线辐射角度不受影响。
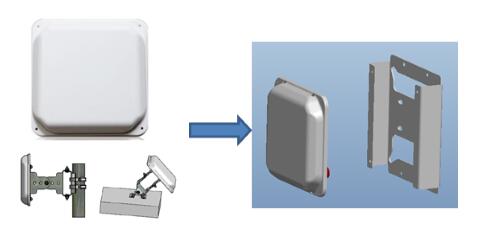
图4定制化的安装件
华为WLAN轨道交通解决方案,从性能、可靠性及定制化等多个方面很好的解决了土耳其UUC地铁Wi-Fi覆盖所面临的问题,保证了地铁监控系统的稳定运行,通过高质量的无线链路切换功能,车地回传的业务质量得到了显著改善,来自移动列车内的实况视频流可以被实时传送到控制中心,帮助操作者进一步提高列车上的操作意识和安全性,为相关机构应对突发事件及民众的安全出行增添了保障。
好文章,需要你的鼓励


奥运级别的努力:首席信息官为2026年AI颠覆做准备
AI颠覆预计将在2026年持续,推动企业适应不断演进的技术并扩大规模。国际奥委会、Moderna和Sportradar的领导者在纽约路透社峰会上分享了他们的AI策略。讨论焦点包括自建AI与购买第三方资源的选择,AI在内部流程优化和外部产品开发中的应用,以及小型模型在日常应用中的潜力。专家建议,企业应将AI建设融入企业文化,以创新而非成本节约为驱动力。

字节跳动发布GAR:让AI能像人类一样精准理解图像任何区域的突破性技术
字节跳动等机构联合发布GAR技术,让AI能同时理解图像的全局和局部信息,实现对多个区域间复杂关系的准确分析。该技术通过RoI对齐特征重放方法,在保持全局视野的同时提取精确细节,在多项测试中表现出色,甚至在某些指标上超越了体积更大的模型,为AI视觉理解能力带来重要突破。

Spotify推出AI播放列表功能让用户掌控推荐算法
Spotify在新西兰测试推出AI提示播放列表功能,用户可通过文字描述需求让AI根据指令和听歌历史生成个性化播放列表。该功能允许用户设置定期刷新,相当于创建可控制算法的每周发现播放列表。这是Spotify赋予用户更多控制权努力的一部分,此前其AI DJ功能也增加了语音提示选项,反映了各平台让用户更好控制算法推荐的趋势。

Inclusion AI推出万亿参数思维模型Ring-1T:首个开源的超大规模推理引擎如何重塑AI思考边界
Inclusion AI团队推出首个开源万亿参数思维模型Ring-1T,通过IcePop、C3PO++和ASystem三项核心技术突破,解决了超大规模强化学习训练的稳定性和效率难题。该模型在AIME-2025获得93.4分,IMO-2025达到银牌水平,CodeForces获得2088分,展现出卓越的数学推理和编程能力,为AI推理能力发展树立了新的里程碑。
2017
01/12
17:20
分享
点赞

为全天候绿电而生,海辰储能发布全球首个原生8小时长时储能解决方案
为AI+而生,海辰储能发布全球首款锂钠协同AIDC全时长储能解决方案
长时储能开启智慧未来:海辰储能生态日全球首发三大新品
Arm 借助融合型 AI 数据中心,重塑计算格局
奥运级别的努力:首席信息官为2026年AI颠覆做准备
Spotify推出AI播放列表功能让用户掌控推荐算法
Adobe押注生成式AI获得回报,年度营收创历史新高
OpenAI与迪士尼达成十亿美元合作协议,米老鼠和漫威角色进入Sora
甲骨文150亿美元数据中心投资导致股价下跌
Spoor鸟类监测AI软件需求飞速增长
制药行业AI数据质量危机:垃圾进垃圾出的隐患
Harness获得2.4亿美元融资,估值达55亿美元,专注自动化AI编码后的开发流程
众智有为 致敬同路人|十年耕耘轨道交通,嘉环诺金点亮一个灯塔
华为乾崑生态大会发布MoLA架构, 鸿蒙座舱率先迈入 L3 智能时代
数智惠闽企,展车进福州|华为坤灵中国行2025·福建站成功举办,推动闽企智能化发展新征程
众智有为 致敬同路人|四川赛狄:从“碰撞”到“同路”,一位华为同路人的蜕变之旅
华为中国行2025·安徽新质生产力峰会 共绘新质生产力发展新图景
众智有为 致敬同路人|从ICT集成商到数智化赋能者,众诚科技的三十载进化论
众智有为 致敬同路人 | 同行之路:坚持长期主义,共赴电力产业新未来
Verizon成立6G创新论坛推动下一代通信技术发展
传祺向往S9上市22.99万起 首批搭载华为乾崑智驾ADS 4+ HarmonySpace 5
华为发布 “4+10+N”中小企业智能化方案,打通迈向智能世界“最后一公里”
