
构建万亿级海量数据平台,巨杉数据库湖仓一体&云产品全线升级 原创
2021年5月15日,领先的金融级分布式数据库厂商SequoiaDB巨杉数据库举行了2021年春季发布会。在本次发布会中,巨杉数据库基于「湖仓一体」架构,针对不同的业务需求场景细分出全新的产品线。同时进行了最新的SequoiaDB Cloud数据库云平台操作演示,并将于近期邀请企业客户进行SequoiaDB Cloud测试。
数字化转型在过去10年间持续带动IT技术发展,今天企业面对的数据环境已经从单一的结构化表单数据,扩展到包括结构化、半结构化和非结构化的多类型业务场景。近年来,面向全新数字化业务的混合数据场景,企业数据量已经形成爆炸性的增长趋势,推动着数据库技术的发展。在2011年首次提出“数据湖 DataLake”的概念后,业界于2020年结合云原生的架构又再次提出“湖仓一体 Data Lakehouse”的定义,让大数据时代迎来了全球变革的一年。

巨杉数据库聚焦于海量数据的全新场景,2011年产品投入研发之初,就专注于多模能力的“数据湖”产品,并于2013年正式发布首个商用版本。2015年后,巨杉数据库更逐步加入数据分析引擎及跨引擎事务一致性能力,为客户提供具备海量联机数据交易及分析能力的「湖仓一体」数据基础设施。在金融银行业生产环境中,巨杉数据库运行时间最长的集群已经超过7年,最大单客户集群规模达300台物理服务器,所管理的单集群最大数据量达到1万2000亿条。无论在物理服务器部署、私有云或公有云环境下,巨杉数据库均能够通过同一套软件架构,实现跨平台、跨底座的快速部署与应用。
巨杉数据库联合创始人兼CTO王涛表示,「湖仓一体」是一类技术架构的统称,而不是某个产品。巨杉数据库对这类技术架构的布局最早可追溯到2015年,在业界形成统一认知的概念之前,就提前5年利用其特点协助客户落地湖仓一体数据架构。当前巨杉数据库已经在民生银行、广发银行、恒丰银行、渤海银行等股份制银行;广东省农信、吉林省农信、四川省农信等省级农信行;上海银行、长沙银行、广州银行等城商农商行;以及PICC人保、中国结算等超过100家头部金融银行业客户规模化生产上线。

「湖仓一体」海量联机交易及分析的数据基础设施
在数字化转型的全新技术趋势中,数据平台需要同时承载联机业务与分析能力,因此Data Lakehouse架构并非单纯为了OLAP分析而设计。Data Lakehouse可以支持联机交易、流处理和分析,并且同时支持结构化、半结构化和非结构化数据的存储。因此,Data Lakehouse作为数据基础设施,其真正的价值在于打通不同业务类型、不同数据类型之间的技术壁垒,实现交易分析一体化、流批一体化、多模数据一体化,最终降低数据流动带来的开发成本及计算存储开销,提升企业的运作的“人效”和“能效”。
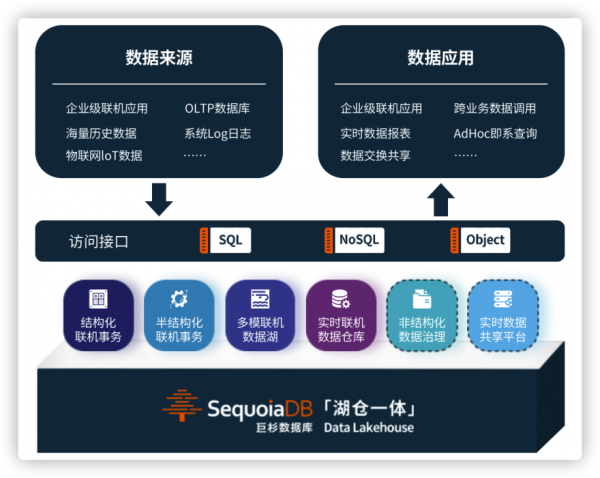
本次发布会中,面向客户对「湖仓一体」各个不同场景的需求,巨杉数据库细分出4大产品线。
- SequoiaDB-DP数据融合平台:面向数据中台的创新数据底座,数据实现一次写入、多引擎实时可读,并提供增强的数据分析引擎。各业务团队间可以充分实现数据融合,实现数据的交易分析一体化、流批一体化、多模数据一体化,让更多业务的海量数据处理能力从T+1提升到T+0。
- SequoiaDB-TP事务型数据库:面向海量数据联机交易及微服务的创新数据底座,兼容3大SQL关系型数据库语法,提供RR数据隔离级别及跨引擎数据一致性能力。开发者可以放心地将事务一致性逻辑,交由数据库层进行处理,并自由地选择需要的SQL引擎,让开发人员回归到纯粹的业务设计,提升企业研发“人效”。
- SequoiaDB-CM内容管理数据库:面向非结构化数据治理的创新数据底座,为其存储的每一个对象赋予标签、描述和内容。企业可以基于这些信息进行统一有效的管理、分类、检索和查询,实现非结构化数据治理。同时实现内容管理平台从“资源消耗中心”向“数据价值中心”转型,提升企业数据管理“能效”。
- SequoiaDB-DOC文档型数据库:提供MongoDB引擎的兼容语法,可以有效协助客户进行文档型数据库的国产化迁移,为信创上下游提供金融级的数据基础设施。
各个产品线均基于统一的SequoiaDB分布式数据库内核,可以按需独立部署,也可叠加使用。基于「湖仓一体」架构,降低数据流动带来的开发成本及计算存储开销,提升企业海量数据处理的“人效”和“能效”。
SequoiaDB Cloud打破部署边界,跨多云灵活部署
近年来越来越多企业开启了“上云之路”,云计算的重要性在业界已经毋庸置疑。企业的云计算落地,往往会按自身的需求,选择使用不同能力的云厂商。一些企业甚至会选择多家云厂商的IaaS平台作为基础设施,这就好比以往我们选择多家服务器厂商构建基础设施一样。作为新一代分布式数据库,SequoiaDB Cloud面向不同的云厂商,提供跨公有云及私有云「跨多云」的部署能力。
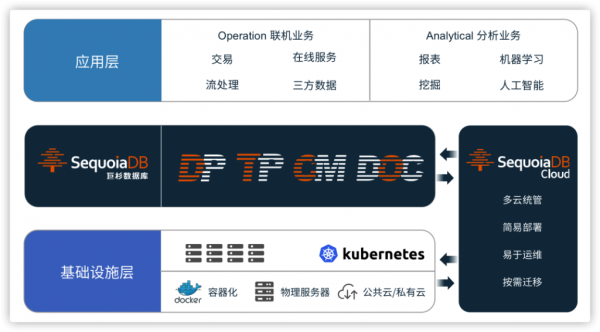
巨杉数据库早在2018年即开启了跨多云统一部署的研发,目前已经形成一套可以同时满足裸机、私有云以及公有云环境部署的平台架构。巨杉数据库已经在多家银行客户实现了基于多厂商云平台的大规模生产环境落地,同时将在今年正式推出订阅模式,进一步实现跨腾讯云、华为云、亚马逊等公有云环境的数据库云服务。
深耕数据沃土,提升数据价值
随着企业数字化转型的深入,企业对海量大数据的实时联机处理(包括联机交易和联机分析)需求越来越迫切。一方面,面对这些全新的应用需求,企业级的商业化产品可从企业的核心诉求出发,稳健地满足企业的应用需求。另一方面,面对业务场景带来的挑战,企业该如何应对底层的数据架构进行变革,湖仓一体无疑提供了明确的变革方向。
巨杉数据库表示,未来巨杉将持续秉承“坚持以客户为中心”的核心价值观,聚焦于「湖仓一体」架构的分布式技术创新,与上下游合作伙伴生态共同深耕数据沃土,提升数据价值,为客户提供安全、稳定、可靠的金融级数据基础设施。
好文章,需要你的鼓励


苹果在印度恢复银行卡支付功能,距暂停已逾四年
苹果已开始在印度分阶段恢复Apple账户的信用卡支付功能,用户可绑定Visa和Mastercard信用卡及借记卡,用于购买iCloud+、Apple Music订阅及App Store应用。此前,由于印度储备银行于2021年推出新的周期性支付监管框架,苹果于2022年5月暂停了该支付方式。此次恢复标志着苹果在适应各国本地化监管要求方面的持续努力,同时也引发外界对苹果是否将在印度推出Apple Pay的新猜测。

腾讯混元团队打破AI“记忆瓶颈“:让大模型像人一样拥有超长记忆的新突破
腾讯混元等机构提出HiLS-Attention,通过端到端可学习的分层稀疏注意力机制,让大模型在超长上下文推理中比全量注意力快14倍,同时检索准确率更高。

Bookshop.org确认今年将推出Kobo电子书阅读器支持
Bookshop.org创始人Andy Hunter证实,与Kobo的合作集成将于今年落地。此前该计划历经多次推迟,网页措辞一度从"2026年"改为"未来某时"。Hunter表示,双方已就商业条款达成一致,工程团队正将资源重新投入Kobo支持开发,但尚无具体上线日期。该集成将支持数字版权管理要求,让用户通过Bookshop.org购买电子书,同时支持独立书店。

DeepSeek-AI与北京大学联手破局:AI聊天机器人“慢速打字“的终极解决方案
DSpark是DeepSeek与北京大学提出的投机解码框架,通过半自回归生成和置信度调度验证两项创新,将DeepSeek-V4用户生成速度提升60%至85%。
2021
05/15
13:36
分享
点赞

苹果在印度恢复银行卡支付功能,距暂停已逾四年
Bookshop.org确认今年将推出Kobo电子书阅读器支持
WeWard新增"步行模式":走够步数才能解锁应用
X将通过私信通知用户其互动帖子被社区笔记纠错
"慢社交"应用Roost:让消息像真鸟一样飞行
Truecaller与印度电信监管机构就反垃圾电话规则展开公开交锋
Block与46州达成4500万美元和解,涉Cash App欺诈纠纷
欧盟威胁对Meta开出罚款,剑指Facebook和Instagram上瘾性设计
Disney+考虑推出免费流媒体内容层级
HyperTexting:将开放网络变成类社交媒体信息流的新应用
TV Time关闭之际,创始人打造新追剧应用Bingers
Telegram短链域名t.me因制裁合规问题短暂下线后已恢复
