
瑞星发布《2021年中国网络安全报告》
近日,瑞星公司发布《2021年中国网络安全报告》,该报告综合瑞星“云安全”系统、瑞星安全研究院、瑞星威胁情报平台、瑞星客户服务中心等部门的数据与资料,针对恶意软件、恶意网址、移动安全、企业安全等领域作出详尽分析,并对未来网络安全趋势提出建设性观点。
报告指出,2021年瑞星“云安全”系统共截获病毒样本总量1.19亿个,病毒感染次数2.59亿次,新增木马病毒8,050万个,为第一大种类病毒,占到总体数量的67.49%,勒索软件样本32.22万个,感染次数为62.4万次;挖矿病毒样本总体数量为485.62万个,感染次数为184.11万次;手机病毒样本275.6万个,病毒类型以信息窃取、资费消耗、远程控制、流氓行为等类型为主。
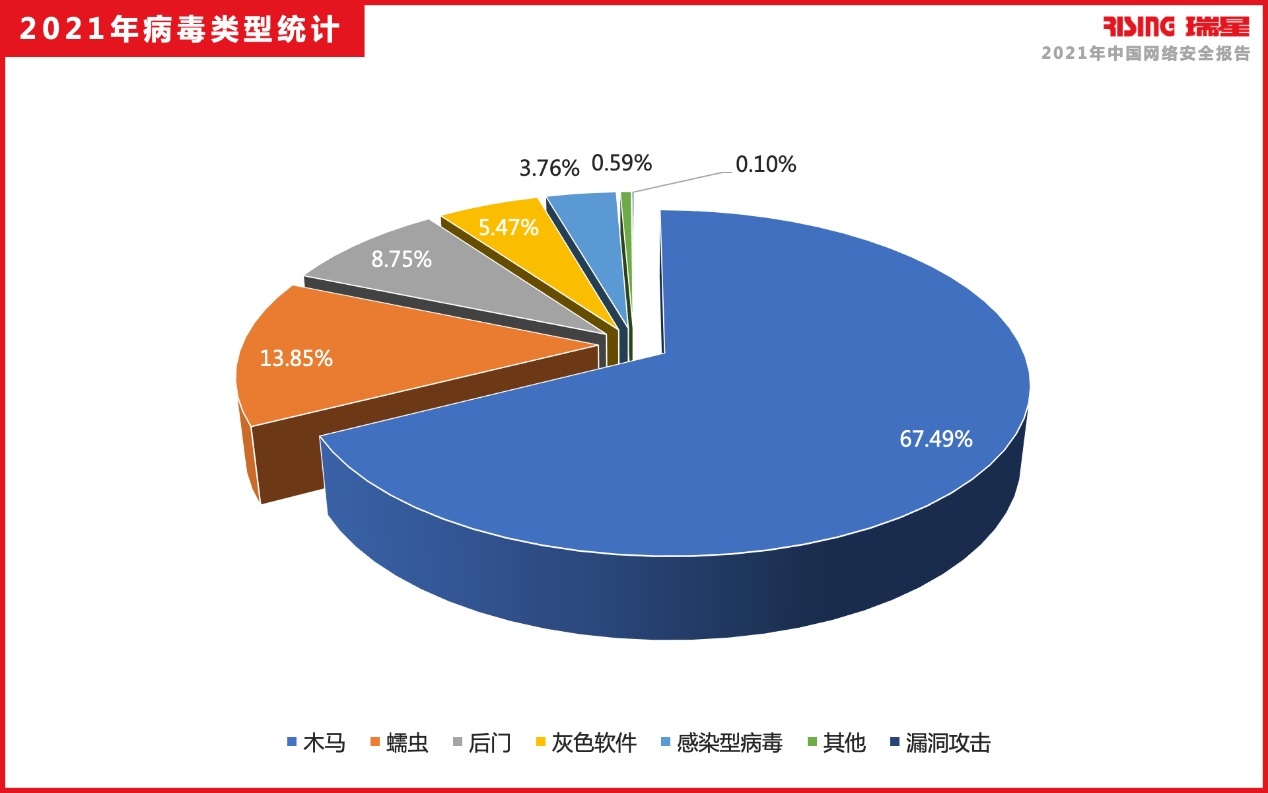
图:2021年病毒类型统计
报告显示,从收集到的病毒样本分析来看,2021年利用最多的漏洞依然是微软Office漏洞,CVE-2017-11882、CVE-2018-0802、CVE-2017-0199得益于漏洞稳定性、易用性和用户群体广泛性始终是钓鱼邮件攻击者首选的利用漏洞。同时,Log4j2远程代码执行漏洞(CVE-2021-44228)作为引爆2021年安全行业的重大事件被着重提及,该漏洞相关利用被公开并迅速的在网络上扩散,引起各国高度重视,一时间全球近一半企业与之相关的业务均受到该漏洞的影响,同时也出现了诸如比利时国防部被不法分子利用Log4j漏洞进行攻击等事件。
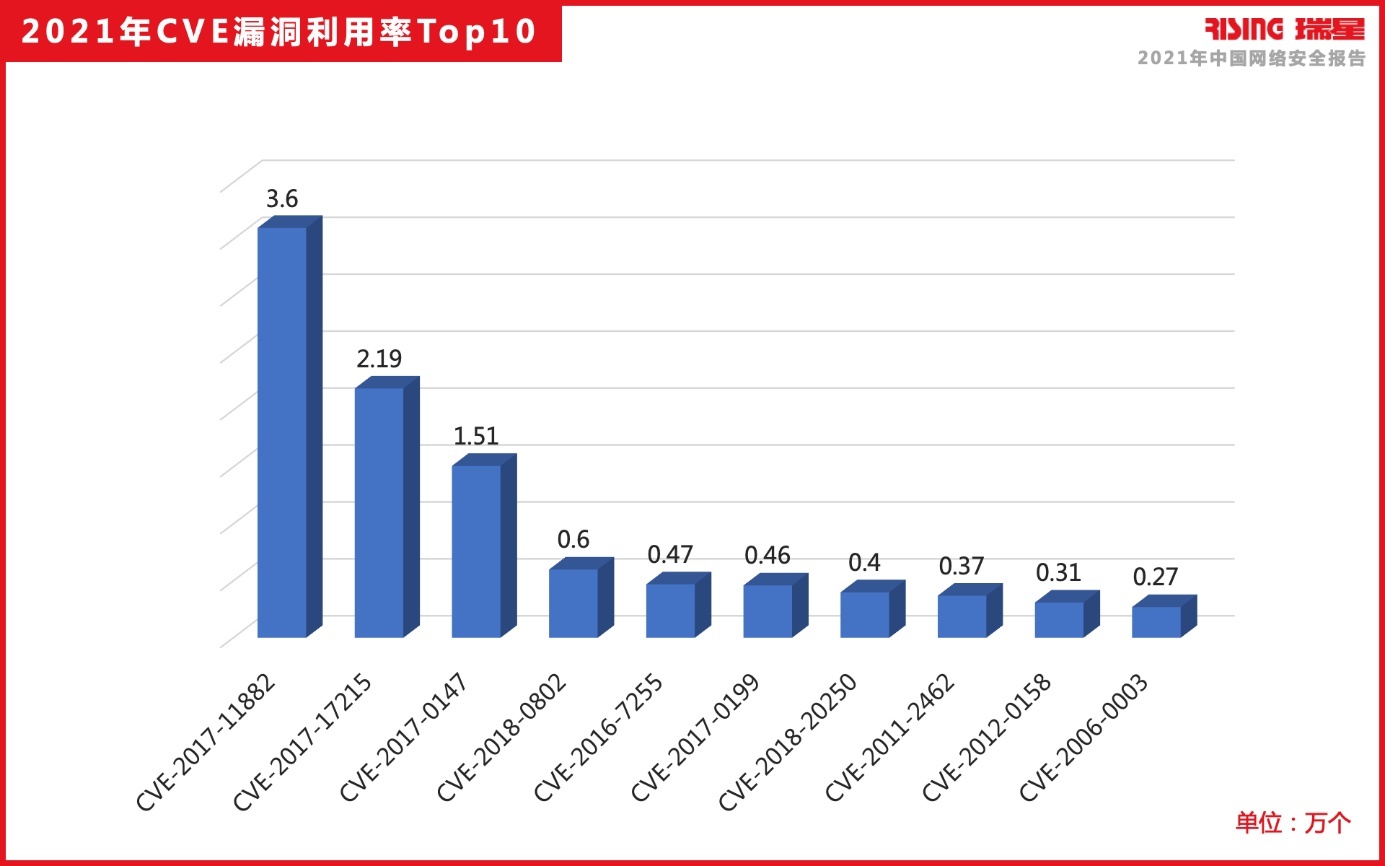
图:2021年CVE漏洞利用率Top10
2021年全球APT攻击也愈发猛烈,报告显示,威胁组织Darkside在短时间内先后对成品油管道运营商Colonial Pipeline、东芝公司(Toshiba Tec Corp)、化学品分销集团Brenntag等企业进行了网络攻击,窃取了大量文件并进行勒索;同时报告对瑞星威胁情报平台所捕获的威胁组织Patchwork、威胁组织Lazarus Group、威胁组织Transparent Tribe、威胁组织SideWinder和威胁组织APT-C-23也都进行详细的介绍。
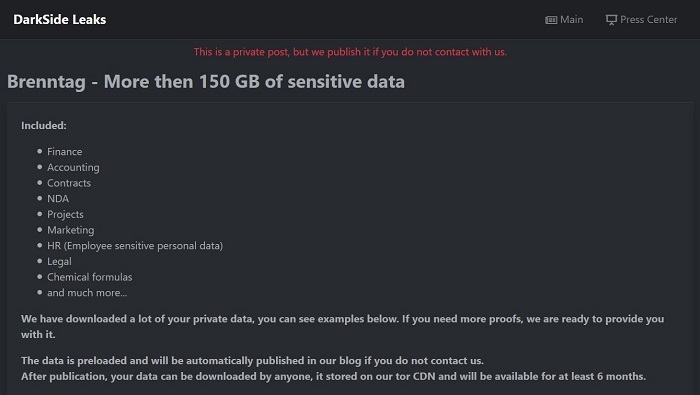
图:DarkSide组织创建的私人数据泄露页面
2021年勒索软件依然猖獗,仍主要针对政府及企业用户,越来越多的威胁组织在勒索的同时,采取文件窃取的方式来“绑架”企业的隐私文件,以历史攻击事件梳理来看这确实卓有成效,大大提高了勒索软件敲诈赎金的成功几率。同时,越来越多的攻击组织或不法分子选择运用勒索软件即服务(RaaS)这一模式进行攻击,让不具备专业技术知识的犯罪分子可以轻而易举的发起网络敲诈活动,这就导致勒索软件市场规模不断扩大。瑞星根据感染量、威胁性筛选出影响较大的年度Top3勒索软件,分别是Sodinkibi勒索软件、Darkside勒索软件和BlackCat勒索软件。
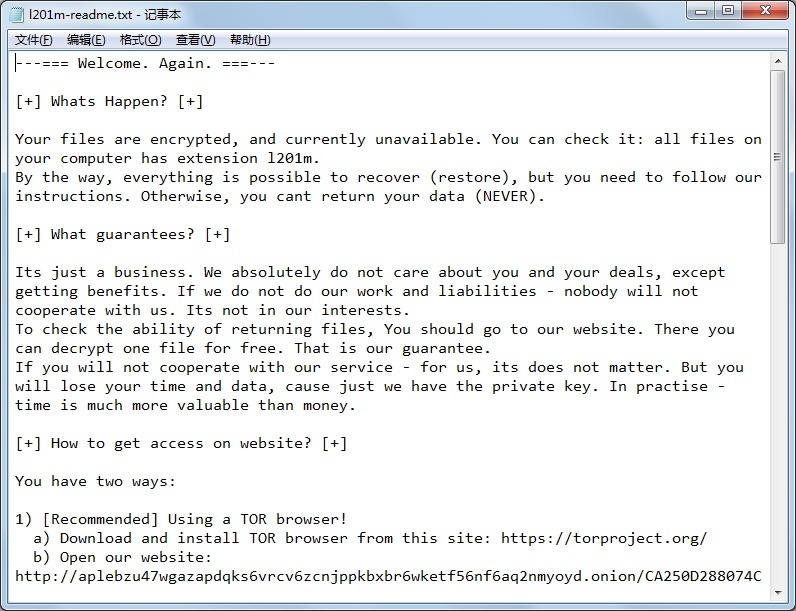
图:Sodinokibi勒索信
《2021年中国网络安全报告》对于未来的网络安全趋势也给出一定的参考意见,报告指出国家级APT攻击活动愈加频繁,通过捍卫网络安全来保护国家安全任重而道远,且勒索软件依然活跃,尤其是关键基础设施和重要行业领域的企业均遭受了勒索软件攻击,建立网络安全综合治理体系,搭建多层防御系统是重中之重。同时,利用成功率极高的漏洞依然受到攻击者的青睐,大量没有更新的老旧软件会成为攻击者的首选利用目标,而Apache Log4j2漏洞的出现则反映出,引用开源项目时需要谨慎,建立事前源代码安全性审查、事后规范化的应急响应将成为软件开发企业必不可少的基础性安全工作。
目前,《2021年中国网络安全报告》 已可下载,广大用户可通过瑞星官网下载获取,了解更加详细的网络安全数据、攻击事件详细分析及未来网络安全形势。
来源:业界供稿
好文章,需要你的鼓励


苹果在印度恢复银行卡支付功能,距暂停已逾四年
苹果已开始在印度分阶段恢复Apple账户的信用卡支付功能,用户可绑定Visa和Mastercard信用卡及借记卡,用于购买iCloud+、Apple Music订阅及App Store应用。此前,由于印度储备银行于2021年推出新的周期性支付监管框架,苹果于2022年5月暂停了该支付方式。此次恢复标志着苹果在适应各国本地化监管要求方面的持续努力,同时也引发外界对苹果是否将在印度推出Apple Pay的新猜测。

腾讯混元团队打破AI“记忆瓶颈“:让大模型像人一样拥有超长记忆的新突破
腾讯混元等机构提出HiLS-Attention,通过端到端可学习的分层稀疏注意力机制,让大模型在超长上下文推理中比全量注意力快14倍,同时检索准确率更高。

Bookshop.org确认今年将推出Kobo电子书阅读器支持
Bookshop.org创始人Andy Hunter证实,与Kobo的合作集成将于今年落地。此前该计划历经多次推迟,网页措辞一度从"2026年"改为"未来某时"。Hunter表示,双方已就商业条款达成一致,工程团队正将资源重新投入Kobo支持开发,但尚无具体上线日期。该集成将支持数字版权管理要求,让用户通过Bookshop.org购买电子书,同时支持独立书店。

DeepSeek-AI与北京大学联手破局:AI聊天机器人“慢速打字“的终极解决方案
DSpark是DeepSeek与北京大学提出的投机解码框架,通过半自回归生成和置信度调度验证两项创新,将DeepSeek-V4用户生成速度提升60%至85%。
2022
01/27
16:07
分享
点赞

苹果在印度恢复银行卡支付功能,距暂停已逾四年
Bookshop.org确认今年将推出Kobo电子书阅读器支持
WeWard新增"步行模式":走够步数才能解锁应用
X将通过私信通知用户其互动帖子被社区笔记纠错
"慢社交"应用Roost:让消息像真鸟一样飞行
Truecaller与印度电信监管机构就反垃圾电话规则展开公开交锋
Block与46州达成4500万美元和解,涉Cash App欺诈纠纷
欧盟威胁对Meta开出罚款,剑指Facebook和Instagram上瘾性设计
Disney+考虑推出免费流媒体内容层级
HyperTexting:将开放网络变成类社交媒体信息流的新应用
TV Time关闭之际,创始人打造新追剧应用Bingers
Telegram短链域名t.me因制裁合规问题短暂下线后已恢复
NHS 医护人员对卫生服务网络安全措施缺乏信心
薄弱的网络防御正在暴露关键基础设施的风险 - 企业如何主动防范精明的攻击者以保护我们所有人
数千个已私有化的 GitHub 代码库仍可通过 Copilot 访问
Check Point 联合创始人谈 AI、量子计算和独立性
Versa 声称重新定义企业级 SASE
告别分享个人手机号的烦恼:Surfshark 虚拟号码服务全新上线
苹果目前仅能检测出一半被感染 Pegasus 间谍软件的 iPhone
网络监测中心设立"飓风等级制"评估网络攻击损失
Deepwatch 收购安全情报公司 Dassana,加强 AI 驱动的网络安全防御能力
AI 驱动的关键基础设施网络安全创企 Dream 以 11 亿美元估值融资 1 亿美元
