
新型变型僵尸网络窃取价值50万美元的加密货币
近日,网络安全解决方案供应企业Check Point 的研究软对Check Point Research (CPR) 发现了一种僵尸网络变体,它通过一种称为“加密货币裁剪”的技术窃取了价值近 50 万美元的加密货币。这一名为 Twizt 的新变体是 Phorpiex 的衍生,可自动将目标钱包地址替换为攻击者的钱包地址,从而在交易过程中窃取加密货币。在过去一段时间内,3.64 比特币、55.87 以太币及 55,000 美元的 ERC20 代币遭到窃取;该僵尸网络主要针对亚洲与非洲加密货币持有者与用户。加密货币交易者与持有者应提高对转账信息的检查力度,Twizt 可以在没有活动 C&C 服务器的情况下运行,进而逃避安全机制。
Check Point Research (CPR) 发现这一名为 Twizt 的新变体可在没有活动命令和控制服务器的情况下运行,这意味着它感染的每台计算机都能够扩大僵尸网络的范围。CPR 估计 Twizt 已经窃取价值近 50 万美元的加密货币。Twizt 的新特性让 CPR 相信该僵尸网络可能会变得更加稳定,因此也更加危险。
Twizt 的攻击流程
Twizt 利用一种称为“加密货币裁剪”的技术,该技术通过利用可自动将目标钱包地址替换为攻击者钱包地址的恶意软件,在交易过程中窃取加密货币,致使资金落入不法之徒手中。
受害者
在 2020 年 11 月至 2021 年 11 月的一年时间内,Phorpiex Bot 劫持了 969 笔交易,窃取了 3.64 比特币、55.87 以太币及 55,000 美元的 ERC20 代币。按现价计算,被盗资产的价值为近 50 万美元。Phorpiex 曾多次得以劫持大额交易。其中一次截获的以太坊交易的最大金额为 26 以太币。
图 1:按国家/地区划分的受害者
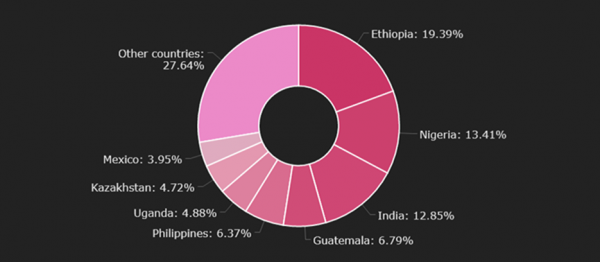
Check Point软件技术公司软件技术公司网络安全研究与创新经理Alexander Chailytko 表示:“Phorpiex 的新变体涉及三个主要风险。首先,Twizt 使用对等模型,可接收来自其他数千台受感染机器的命令和更新。摧毁对等僵尸网络并中断其运行要困难得多。这使得Twizt 比早期版本的 Phorpiex Bot 更加稳定。其次,与旧版 Phorpiex 一样,Twizt 能够在不与 C&C 进行任何通信的情况下窃取加密货币,因此更容易逃避安全机制(例如防火墙)以进行破坏。第三,Twizt 支持来自不同区块链的 30 多种不同的加密货币,包括比特币、以太坊、达世币、门罗币等主要加密货币。这就造成了一个巨大的攻击面,基本上使用加密货币的任何用户都可能受到影响。因此,Check Point强烈建议所有加密货币用户仔细检查其复制和粘贴的钱包地址,因为交易很可能将用户的加密货币送入攻击者手中。”
安全操作确保财产安全
为避免用户财产遭到损失,Check Point建议加密货币用户在执行操作时着重关注以下几个重要事项:1.检查钱包地址:当用户复制和粘贴加密钱包地址时,请务必仔细检查原始地址与粘贴地址是否相符;2.测试交易:在发送加密货币前,首先发送一笔最低金额的试探“测试”交易;3. 保持更新。确保操作系统及时更新,切勿从未经验证的来源下载软件;4.平台检查。如果用户正在寻找加密钱包或加密交易和交换平台,请务必仔细审查搜索结果中网站,并尽量对该平台进行多方核实。
随着近几年加密货币受关注程度不断提升,很多对区块链、加密货币安全缺乏了解的用户也在陆续尝试持有或使用加密货币,这就导致不法分子将不断尝试攻击以获得不法收入。因此,Check Point安全专家建议用户应首先提高安全意识,避免任何存疑操作,从而在最大程度上保障个人财产安全。
来源:业界供稿
好文章,需要你的鼓励


苹果在印度恢复银行卡支付功能,距暂停已逾四年
苹果已开始在印度分阶段恢复Apple账户的信用卡支付功能,用户可绑定Visa和Mastercard信用卡及借记卡,用于购买iCloud+、Apple Music订阅及App Store应用。此前,由于印度储备银行于2021年推出新的周期性支付监管框架,苹果于2022年5月暂停了该支付方式。此次恢复标志着苹果在适应各国本地化监管要求方面的持续努力,同时也引发外界对苹果是否将在印度推出Apple Pay的新猜测。

腾讯混元团队打破AI“记忆瓶颈“:让大模型像人一样拥有超长记忆的新突破
腾讯混元等机构提出HiLS-Attention,通过端到端可学习的分层稀疏注意力机制,让大模型在超长上下文推理中比全量注意力快14倍,同时检索准确率更高。

Bookshop.org确认今年将推出Kobo电子书阅读器支持
Bookshop.org创始人Andy Hunter证实,与Kobo的合作集成将于今年落地。此前该计划历经多次推迟,网页措辞一度从"2026年"改为"未来某时"。Hunter表示,双方已就商业条款达成一致,工程团队正将资源重新投入Kobo支持开发,但尚无具体上线日期。该集成将支持数字版权管理要求,让用户通过Bookshop.org购买电子书,同时支持独立书店。

DeepSeek-AI与北京大学联手破局:AI聊天机器人“慢速打字“的终极解决方案
DSpark是DeepSeek与北京大学提出的投机解码框架,通过半自回归生成和置信度调度验证两项创新,将DeepSeek-V4用户生成速度提升60%至85%。
2021
12/30
14:43
分享
点赞

苹果在印度恢复银行卡支付功能,距暂停已逾四年
Bookshop.org确认今年将推出Kobo电子书阅读器支持
WeWard新增"步行模式":走够步数才能解锁应用
X将通过私信通知用户其互动帖子被社区笔记纠错
"慢社交"应用Roost:让消息像真鸟一样飞行
Truecaller与印度电信监管机构就反垃圾电话规则展开公开交锋
Block与46州达成4500万美元和解,涉Cash App欺诈纠纷
欧盟威胁对Meta开出罚款,剑指Facebook和Instagram上瘾性设计
Disney+考虑推出免费流媒体内容层级
HyperTexting:将开放网络变成类社交媒体信息流的新应用
TV Time关闭之际,创始人打造新追剧应用Bingers
Telegram短链域名t.me因制裁合规问题短暂下线后已恢复
Check Point:以AI技术赋能云端交付平台化安全解决方案
Check Point 推出全新 SaaS 威胁防御解决方案
Check Point:2024年,企业应积极推进行云安全变革
Check Point推出 ThreatCloud Graph:从多维视角评估网络安全态势
Check Point:网络安全发展历史大事记
Check Point+七云网络 强强共建SD-WAN安全
沃尔玛成为 2023 年第三季度网络钓鱼诈骗中最常被冒充的品牌
服务出海 Check Point全面防御内外威胁
Check Point 软件技术公司通过全新安全托管功能增强了 Infinity 全球服务
Check Point Software 第三季度业绩超预期
