
新世界,新机遇 Check Point全面守护用户网络架构,助力用户恢复业务发展 原创
疫情肆虐的2020注定会被长久铭记。在这一年中,人们的工作、生活方式发生了巨变。在Check Point全球进行的调查中显示,87%的工作人口采用了居家办公模式,74%的企业在2021年仍然希望采取远程或混合办公模式。全球范围内互联网使用时间激增、使用环境趋向复杂已成为后疫情时代“新世界”的主要标志之一,而这也为网络不法分子提供了攻击的温床。Check Point报告显示,71%的受访安全从业者表示其所在机构的网络受威胁次数明显上升;近半年来约68,000个新注册新冠相关域名中,近半数高度疑似恶性钓鱼网站。这些趋势使得企业与机构不得不重新审视网络的安全架构,以及安全解决方案在企业恢复业务阶段需要承担的角色。

Check Point中国区总经理陈石磊先生在分享中表示:“作为信息安全领域的长期领导者,Check Point有能力从用户的需求出发,在这个特殊的时期帮助用户以最高级别的安全防御能力快速部署、恢复自己的核心业务。在2020年,Check Point将自己的企业愿景调整为“Secure Your Everything”- “全面防护“,其原因在于公司明确感受到疫情加速了第五代网络威胁普及的范围与速度。面对这种跨地域、跨环境、多维度的攻击,用户需要一个以主动预防为主、能够快速调配安全资源,并能统一管理的安全解决方案。因此Check Point在今年3月推出了一整套全方位安全架构,以及覆盖各个网络环境的解决方案。“

Check Point中国区技术总监王跃霖先生在会上详细介绍了公司推出的全方位安全架构。王先生表示:“Check Point为用户打造了全新的安全架构体系,包括对应网络安全的Quantum系列解决方案,对应云安全的CloudGuard系列解决方案以及对应终端和远程用户安全接入的Harmony系列解决方案。这些安全方案都能通过Check Point的Infinity管理平台进行便捷、统一的管理,并且全部由业内领先的ThreatCloud安全威胁情报云实时提供最新威胁库。
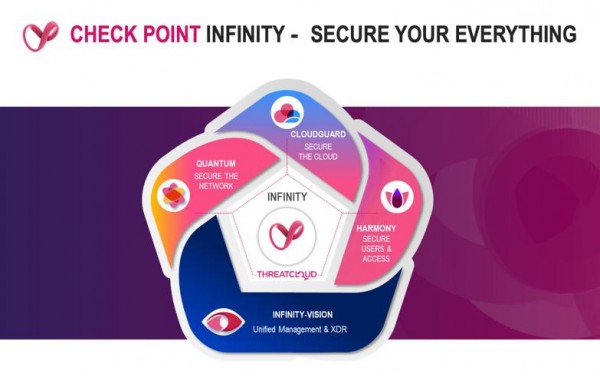
尤其需要指出的是,2020年下半年ThreatCloud落户中国,使我们国内的用户可以更加快捷、无缝的介入全球最大的威胁情报服务系统,在提升预防未知威胁、零日威胁的同时,保障了特定行业对于敏感信息的合规性要求。”

渠道总监邹佳蕾女士在介绍渠道策略时强调:“Check Point中国将通过丰富的渠道策略,全面的培训体系以及灵活的奖励机制打造一个可以持续成长的合作伙伴生态体系。通过这个体系,我们不仅将为用户提供符合需求的解决方案,更将有能力为用户提供全面安全服务,使我们的团队真正成为用户可以信赖的安全顾问。”
刚刚过去的2020年是人类历史上极不平凡的一年,全球人民一同经历了疫情,也将一同携手战胜疫情。陈石磊先生在总结本次会议时指出:2021年,随着中国率先进入到经济恢复期,全球经济也将逐渐重启。Check Point有信心帮助中国、以及全球的用户安全、快速的恢复业务发展,早日摆脱疫情影响,回归正常业务轨道。
来源:业界供稿
好文章,需要你的鼓励


遭黑客入侵的Klue称犯罪分子正在删除窃取的客户数据,但新的黑客组织接连发出威胁
市场研究公司Klue本月初遭黑客入侵,大量客户数据被窃。Klue表示正与黑客组织Icarus沟通,并相信对方正在删除所盗数据。受影响客户包括Gong、LastPass、HackerOne等多家知名企业。然而事态趋于复杂——另一黑客团伙声称从Icarus处获取了Klue客户数据,并向客户发出勒索威胁。Klue提醒客户勿向第二方支付赎金,并建议索取数据样本以核实其真实性。

机械手臂终于学会“看深度“了——KAIST联合POSTECH研究团队让机器人规划与执行真正说同一种语言
KAIST等机构提出3D HAMSTER,通过为视觉语言模型加入深度编码器和几何重建损失,让机器人规划器直接输出三维轨迹,解决了分层机器人系统中规划与执行的维度不匹配问题,显著提升了操作鲁棒性。

苹果起诉OpenAI窃密:前员工利用零日漏洞下载机密文件
苹果公司对OpenAI提起诉讼,指控其窃取商业机密。据披露,前苹果系统电气工程师刘畅(Chang Liu)在离职加入OpenAI后,利用一个此前未知的身份验证零日漏洞,持续数周从苹果内部网络存储中下载大量机密文件,内容涵盖未发布产品信息、工程演示文稿及技术规格等。苹果已修复该漏洞并终止相关访问权限。此案已提交加州北区联邦法院,并要求陪审团审判。

南京大学团队打造的“轻量AI视频助理“:不用反复推理,一眼就能看懂你的过去
南京大学提出Light-Omni框架,通过全局状态与潜在状态双机制,让AI视频助理无需反复推理即可实现精准记忆检索,速度提升逾12倍,准确率同步提高。
2021
03/26
17:38
分享
点赞

Whatnot收购AI推荐公司Shaped,强化直播购物实时个性化能力
ELIZA:首个聊天机器人背后的多重人格与隐藏秘密
研究显示特斯拉LFP电池健康度表现优于镍基电池
苹果携手阿里云通义千问,Apple Intelligence获批在华上线
微软借助AI发现漏洞,单次发布破纪录的570个安全补丁
AI音乐生成器Suno遭入侵,疑从YouTube抓取训练数据
OpenAI首款品牌硬件亮相:RGB迷你键盘助力Codex智能体监控
PrivadoVPN 推出 MCP 服务器,让 AI 智能体直接管理你的 VPN 连接
Stripe与Advent据报出价约534亿美元联合收购PayPal
微软裁员背后的AI影响:你需要了解什么
Ode with Anthropic:押注AI服务成为企业级市场未来
用Gemini几分钟规划你的暑期旅行
NHS 医护人员对卫生服务网络安全措施缺乏信心
薄弱的网络防御正在暴露关键基础设施的风险 - 企业如何主动防范精明的攻击者以保护我们所有人
数千个已私有化的 GitHub 代码库仍可通过 Copilot 访问
Check Point 联合创始人谈 AI、量子计算和独立性
Versa 声称重新定义企业级 SASE
告别分享个人手机号的烦恼:Surfshark 虚拟号码服务全新上线
苹果目前仅能检测出一半被感染 Pegasus 间谍软件的 iPhone
网络监测中心设立"飓风等级制"评估网络攻击损失
Deepwatch 收购安全情报公司 Dassana,加强 AI 驱动的网络安全防御能力
AI 驱动的关键基础设施网络安全创企 Dream 以 11 亿美元估值融资 1 亿美元
