
随着新冠病毒再次抬头,针对医疗机构的攻击在全球范围内激增
近一段时间,Check Point公司安全报告中指出,医院和医疗机构已经成为越来越多勒索软件攻击的目标,其中大多数攻击都使用了臭名昭著的 Ryuk 勒索软件。在此之前,网络安全与基础设施安全局 (CISA)、联邦调查局 (FBI) 和美国卫生与公众服务部 (HHS) 发布了 联合网络安全公告,警告称医院和医疗服务提供商面临的网络威胁日益增加,形势十分严峻。
不幸的是,近两个月来,这些网络犯罪威胁变得越来越猖獗。自 11 月初起,全球针对医疗机构的攻击又增加了 45%,是同期全球所有行业网络攻击总增幅的两倍多。
攻击的增加与各种媒介有关,包括勒索软件、僵尸网络、远程代码执行和 DDoS 攻击等。 但是,与其他行业相比,勒索软件在医疗领域的增长幅度最大,是医疗机构面临的最大恶意软件威胁。针对医院和相关机构的勒索软件攻击尤其具有破坏性,因为其系统发生任何中断都有可能影响对患者的诊治,并危及生命 — 所有这些又都因抗击新冠疫情的压力而进一步加剧。正因如此,网络犯罪分子才会更加肆无忌惮地攻击医疗行业:因为他们知道医院已经无暇抽身,更有可能交付赎金来了事。
全球攻击概述
- 自 11 月 1 日以来,全球针对医疗机构的攻击数量增加了 45% 以上,而针对其他行业的攻击平均增加了 22%。
- 11 月份每个医疗机构平均每周遭到 626 次网络攻击,而 10 月为 430 次。
- 与勒索软件、僵尸网络、远程代码执行和 DDoS 有关的攻击在 11 月份都有所增加。与其他行业相比,勒索软件攻击在医疗领域的增幅最大。
- 攻击中使用的主要勒索软件变体是 Ryuk,其次是 Sodinokibi。
区域攻击数据
在受医疗机构攻击激增影响最大的地区中,中欧高居榜首,11 月增长了 145%;其次是东亚和拉丁美洲,分别增长了 137% 和 112%。欧洲和北美分别增长了 67% 和 37%。
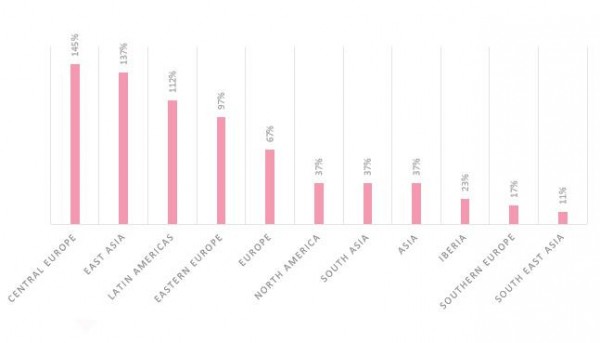
各个地区医疗领域的攻击增长情况
就具体的国家/地区而言,加拿大的攻击增幅最大,高达 250% 以上,其次是德国,增长了 220%。西班牙医疗机构遭到的攻击次数增加了一倍。
为何攻击激增?
这些黑客的主要动机是金钱,他们想在短时间内谋取暴利。在过去的一年中,网络犯罪分子通过这些攻击赚的盆满钵满,这种成功让他们变得欲壑难填。
如上文所述,由于新冠肺炎病例持续增加,医院承受着巨大的压力,他们愿意用支付赎金的方式来换取安心的医疗服务环境。9 月,德国当局报告称,一次定向错误的黑客攻击导致杜塞尔多夫一家大型医院的 IT 系统出现故障,一名需要紧急入院的女性患者在被送往其他城市接受治疗后死亡。任何医院或医疗机构都不希望这种不幸再次发生,为了最大限度地减少中断,他们更有可能满足攻击者的要求。
另外需要指出的是,普通勒索软件攻击通过大规模垃圾邮件和漏洞利用工具广泛传播,而使用Ryuk 变体对医院和医疗机构发起的攻击具有高度定制性和明显的针对性。Ryuk 最早发现于 2018 年年中,不久之后,Check Point Research 便发布了对这种以美国为目标的新型勒索软件的首次全面分析。2020 年,CPR 的 Check Point 研究人员对全球范围内的Ryuk 活动进行了监控,发现 Ryuk 在针对医疗行业的攻击中的使用有所增加。
疫情之下的网络安全格局
此次疫情影响了我们生活的方方面面,网络安全形势也未能幸免。从新冠病毒相关恶意域的注册激增,到使用疫情话题进行网络钓鱼和勒索软件攻击,甚至是出售新冠病毒疫苗的欺诈广告,网络漏洞利用程序数量空前增长,并且均以破坏个人数据、传播恶意软件和窃取金钱为目的。
医疗服务和研究组织成为攻击目标,攻击者试图窃取有价值的商业情报和专业资讯,或破坏重要的研究工作。用于追踪个人的测试和追踪应用曾引发有关隐私的强烈争议,现今已在全球范围内得到广泛采用,并且预计在疫情过后仍将继续使用。由于全球焦点持续集中在抗疫上,网络犯罪分子也在不断设法利用这一点来达到自己的非法目的 —— 因此,组织和个人都必须保持良好的网络安全意识,以防落入黑客以疫情为诱饵的圈套。
勒索软件和网络钓鱼攻击防范技巧
- 注意木马感染 — 勒索软件攻击并非始于勒索软件。Ryuk 和其他类型的勒索软件程序通常都从植入木马病毒入手。这种木马感染通常发生在勒索软件攻击开始前的几天或几周,因此专业安全人员应提防网络感染 Trickbot、Emotet、Dridex 和 Cobalt Strike,使用威胁搜寻解决方案消除这些病毒,避免为 Ryuk 打开大门。
- 周末和节假日提高警惕 — 近一年来,大多数勒索软件攻击都发生在 IT 和安全人员较少值班的周末和节假日。
- 使用反勒索软件解决方案 — 虽然勒索软件攻击很复杂,但具有补救功能的反勒索软件解决方案可有效帮助组织在遭到感染后的短短几分钟内恢复正常。
- 对员工进行有关恶意电子邮件的培训:培训用户如何识别和避免潜在的勒索软件攻击至关重要。当前的许多网络攻击都始于一封有针对性的网络钓鱼电子邮件,该电子邮件甚至不包含恶意软件,只包含一则引诱用户点击恶意链接或提供特定信息的社交工程消息。培训用户识别这些类型的恶意电子邮件通常是组织可以部署的最重要的防御措施之一。
- 虚拟补丁 — 联邦调查局的建议是对旧版软件或系统打补丁,但这对于医院来说是不可能的,因为在许多情况下系统无法打补丁。因此,我们建议使用具有虚拟打补丁功能的入侵防御系统IPS,防止黑客尝试利用脆弱系统或应用中的漏洞。IPS 将保持更新,确保您的组织受到保护。
来源:业界供稿
好文章,需要你的鼓励


OpenAI在版权诉讼中疑因隐瞒证据遭遇重大危机
OpenAI在与多家新闻机构的版权诉讼中陷入困境。以《纽约时报》为首的原告指控OpenAI在长达两年时间里向法庭撒谎,刻意隐瞒其已对ChatGPT日志进行大规模搜索的事实。据悉,OpenAI实际上已拥有包含1000万和7800万条记录的日志样本,并曾用于研究版权内容过滤器,却对外声称无法进行此类搜索。原告据此提出制裁动议,要求法院追责。OpenAI则否认相关指控,坚称其立场基于合理使用原则。

当AI学会“挑剔“:斯坦福与伯克利联手打造的智能验证框架,让AI自己检验自己的答案
斯坦福与UC伯克利提出LLM-as-a-Verifier框架,通过提取AI模型内部概率分布生成连续评分,在代码、机器人、医疗领域均达到最优性能,且无需额外训练。

外科医生远程操控人形机器人,完成全球首例活猪手术
美国加州大学圣地亚哥分校研究团队在《自然》期刊发表研究成果:外科医生通过远程操控宇树G1仿人机器人,成功完成两例活体猪胆囊切除手术,创下全球首例。与造价数十至数百万美元的达芬奇手术机器人相比,仿人机器人成本更低、体积更小,未来有望部署于农村、战地乃至太空等资源匮乏的医疗场景。但目前仍存在需频繁重新校准、机械臂活动范围受限等挑战。

字节跳动Seed团队发现:AI智能体学习新任务的速度,正以每三个月翻倍的惊人节奏增长
字节跳动Seed团队发现AI智能体在真实环境中学习的进步曲线精确遵循对数S形规律,R?达0.998,且前沿模型的学习速度每三个月翻倍。
2021
01/07
10:58
分享
点赞

OpenAI在版权诉讼中疑因隐瞒证据遭遇重大危机
外科医生远程操控人形机器人,完成全球首例活猪手术
OpenAI发布ChatGPT Work:AI助手可连续工作数小时
欧盟向Meta施压:关闭自动播放和无限滚动,否则面临巨额罚款
世界模型的潜力与局限:它真的能模拟一切吗?
苹果起诉OpenAI:前员工利用系统漏洞窃取商业机密
如何利用开源AI智能体实现工作流程自动化
Cloudzy 云服务评测:VPS 性能与体验全面解析
这款PCIe插卡内置38核至强处理器与64GB内存,堪称完整服务器
是否该为企业招募数字员工?AI 智能体团队搭建全指南
AI赋能自主机器人:从工厂走向家庭的未来图景
数据中心能源需求威胁特朗普"美国制造"计划
对象存储防勒索升级:XEOS 国内首家通过 NBU 对象锁认证
Gartner发布企业备份供应商魔力象限报告,Veeam排名喜人
AWS介绍内部Mithra威胁情报系统
Commvault:2024已经过半,网络威胁局势有何变化?
Check Point:以AI技术赋能云端交付平台化安全解决方案
Check Point 推出全新 SaaS 威胁防御解决方案
Check Point:2024年,企业应积极推进行云安全变革
Check Point推出 ThreatCloud Graph:从多维视角评估网络安全态势
Check Point:网络安全发展历史大事记
Check Point+七云网络 强强共建SD-WAN安全
