
关于Tungsten Fabic版本问题,这一篇文章说清了
对于一个开源软件来说,选择适当的版本尤其重要,其对应支持的平台版本、新增和更新的功能、bug修复和稳定性等因素,是平台集成和二次开发工作的基础条件,毕竟没有人想要因为版本问题无限填坑。不过,Tungsten Fabic发行版本的命名规则总在变化,更新节奏也比较快,给社区成员带来了一定的混乱。本文将就TF的版本发行和更迭做一个简单梳理。
发布流程
Tungsten Fabic的发布流程是:commit → review → test → integration → build → release。到最后的release阶段,就已经是正式对外发行的版本,本文提到的版本只针对release发行版本。
版本号命名规则
OpenContrail阶段到Tungsten Fabric早期
传统的“X.X”方式。
2019年7月~2019年12月
5.1版本之后,改为“年.月”,陆续更新了1907、1908、1909、1910、1911、1912等版本,每月都有新版本发行。
2020年至今
改为每季度一次,今年一共有2003、2005、2008三个版本,预计12月将发行本年度最后一个版本——2011版。
最新版进度
https://wiki.tungsten.io/display/TUN/2011+Release+Overview
在近期一次TSC(Tungsten Fabric社区技术指导委员会)例会上,社区决定再次调整命名方案,按照发行节奏,更改为“年.季度”,并承诺以后不再调整。因此,明年的第一个版本号将为R21.1,预计在2月或3月发行。
最后,需要提醒大家的是,Tungsten Fabic社区和瞻博网络在版本发行周期上并不同步,前者为六个月一次,后者Contrail Networking为每季度一次,并且目前来看,两边都将保持自己的发布节奏。
我们将这一年的发行版本(覆盖R5.1-R2008),做了简单整理,包括版本名称、发行/修订时间、新增或更改的功能等信息,部分版本详细列出了平台支持情况,供大家参考。
R2008
发行/修订时间
2008修订版1:2020年9月
2008修订版2:2020年9月
新增或更改功能
- 支持快速路由融合
- 可配置的XMPP Timeout
- 支持Red Hat OpenShift 4.4
- 支持Red Hat OpenStack Platform Director 16.1
- 同一服务器上的Contrail Insights和Contrail Insights流
- 增强的作业状态监控能力
- 在MX系列设备上支持无中断软件升级
- 使用MX系列设备连接到第三方网络设备
- 虚拟端口组创建过程中重新设计的VLAN分配功能
- 在拓扑视图中查看数据包路径
- 端口配置文件属性和参数
- DPDK vRouter(部署在VLAN接口)的VLAN转发禁用功能
- 使用Wireshark插件分析vRouter和vRouter代理之间的流量
- 支持查看已启用DPDK的vRouter的详细信息
- vRouter中的数据包延迟改进
- 支持忽略手动CLI配置更改
- 支持清除vif统计计数器
- Contrail工具容器
- 支持DPDK版本19.11
- Sandump工具
- 在Kubernetes环境中使用Juju部署Contrail Command并导入Contrail集群
- 对可选Contrail Analytics模块的启用更改
- 支持用于Fabric管理的模块化第2层插件连接(Beta版)
- 用于Contrail Networking和Contrail Insights的OVA软件包
平台支持情况
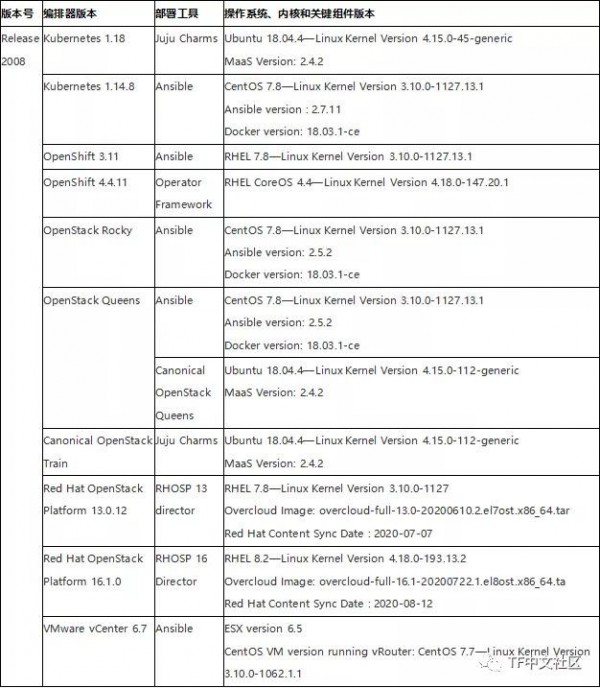
R2005
发行/修订时间
2005修订版1:2020年6月
2005.1修订版2:2020年7月
新增或更改功能
- 子集群间路由过滤
- 支持Kubernetes 1.14.8
- 零影响升级:升级Contrail Networking软件,而无需重新启动计算节点(使用内核模式vRouter)
- 零影响升级:使用Ansible部署的环境中的Contrail Networking软件升级
- 在规范的Openstack环境中使用Juju部署Contrail命令和导入Contrail集群
- 使用Contrail Insights和Contrail Insights Flows增强Contrail Command安装的安装功能
- 在Contrail中添加或删除Flow Collector节点
- 在MX系列路由器上配置DCI-网关角色
- 增强的路由策略以在Contrail Networking中支持QFX系列设备
- 使用eBGP、静态路由、OSPF和PIM路由协议配置BFD
- 支持配置PIM和OSPF路由协议
- Contrail Networking中对逻辑路由器互连的支持
- 支持Octavia作为LBaaS
- Contrail Command中的新增功能
平台支持情况

R2003
发行/修订时间
Contrail Networking 2003修订版1:2020年3月
Contrail Networking 2003.1修订版2:2020年4月
新增或更改功能
- Contrail Command UI Navigation更新
- Contrail Enterprise多云面板入门
- 在MX系列路由器上配置CRB-Gateway,ERB-UCAST-Gateway和CRB-MCAST-Gateway角色
- Contrail Command中的Canonical Openstack支持
- 配置文件克隆
- 增强的DPDK vRouter性能(通过全CPU分区和隔离)
- MX系列路由器的Greenfield Fabric入门
- 基于主机的防火墙(用于内部虚拟网络流量)-Beta版
- 使用Contrail Command登录到域
- 多云网络的独立证书
- 支持连接到不受Contrail Networking管理的第三方设备
- 支持创建路由虚拟网络和路由虚拟端口组
- 支持重新配置物理路由器
- 支持查看在Contrail Fabric中部署设备的配置
- Contrail Command中的前N个视图
平台支持情况

R1912
发行/修订时间
Contrail Networking 1912修订版1:2019年12月
Contrail Networking 1912.L1修订版2:2020年3月
Contrail Networking 1912.L2修订版2:2020年6月
Contrail Networking 1912.L3修订版2:2020年9月
新增或更改功能
- 将服务链功能扩展到裸机服务器
- 监视Fabric作业
R1911
发行/修订时间
Contrail Networking 1911修订版1:2019年11月
新增或更改功能
- 添加Leaf或Spine设备到Greenfield Fabric
- 通过Contrail Command UI配置AppFormix流程
- 对Google云平台的支持
- 对Packer的支持
- 设备功能组和分组结构设备
- 支持增加vRouter下一跳限制并监视下一跳和MPLS标签使用情况
- HA集群中对ZTP的支持
R1910
发行/修订时间
Contrail Networking 1910修订版1:2019年10月
新增或更改功能
- Analytics API服务器和客户端服务器之间的加密支持
- 增强的路由策略以支持修改虚拟网络中的辅助路由
- 支持在Contrail Networking Fabric中终止正在进行的作业
- 支持VMware与Contrail Networking Fabric的集成
- 支持监视启用DPDK的绑定接口
- 支持Contrail Networking和Neutron之间的中继网络
- 精简部署中对QFX5120-32C设备的支持
- 查看Overlay路由信息
R1909
发行/修订时间
Contrail Networking 1909修订版1:2019年9月
新增或更改功能
- 虚拟网络的增强型VLAN ID分配
- 在数据中心设备上执行运维活动
- 支持使用Juju Charms在嵌套模式下集成Kubernetes
- 支持QFX10002-60C设备
- 支持QFX5120-32C设备
- 查看数据中心设备的硬件清单
R1908
发行/修订时间
Contrail 1908修订版1:2019年8月
新增或更改功能
- 在接口上配置风暴控制
- 支持端口配置文件
- 在Fabric创建过程中支持QFX设备的企业样式配置
- 支持4字节AS Number
- Redis流量的加密支持
- 支持使用Juju Charms在Kubernetes上部署Contrail Networking
- 支持添加DHCP服务器信息
- 支持RMA之后的设备镜像升级
- 支持Netronome SmartNIC vRouter
R1907
发行/修订时间
Contrail 1907修订版1:2019年7月
新增或更改功能
- 在数据中心设备上配置Assisted Replication
- 在ZTP期间升级设备
- 在ZTP期间为数据中心设备配置主机名
- 支持退货授权
- Contrail Command中的拓扑视图
- 使用Red Hat快进升级程序升级Contrail Networking
R5.1
发行/修订时间
Contrail 5.1修订版1:2019年4月
新增或更改功能
- Contrail多合一集群
- BGPaaS对等区域选择
- 使用Contrail Command部署企业多云
- 使用Mesos安装Contrail
- 使用TripleO将Contrail集群数据导入到Contrail Command
- 使用Mesos将Contrail集群数据导入到Contrail Command
- 使用VMware vCenter将Contrail集群数据导入到Contrail Command
- LR间流量的3层PNF服务链
- 将新的计算节点添加到现有的容器化Contrail集群中
- 策略生成功能
- PostgreSQL支持
- 支持边缘路由桥接
- 扩展社区上的路由策略匹配
- 支持OpenShift 3.11
- 支持Kubernetes 1.12
- 在Contrail节点上自动配置IPtable过滤规则
- 使用Red Hat Identity Management进行证书生命周期管理
- 支持对虚拟机接口上可支持最大流量规模的控制功能
- 使用Contrail Command进行端到端数据中心ZTP和Contrail集群配置
- 支持数据中心互连
- 支持使用Contrail Command部署独立的Kubernetes集群
- Contrail Command中对AppFormix的支持
- 在Kubernetes中支持多网络接口
- 支持基于前缀的Fat Flow
- 启用Analytics和Kafka之间的TLS通信
- 支持Route Reflectors
- 在Windows操作系统上支持Contrail
- 通用设备操作命令
- 支持EVPN组播Type 6选择性组播以太网标签路由
- 支持MPLS L3 VPN InterAS Option C
- 支持虚拟端口组
平台支持情况

来源:业界供稿
好文章,需要你的鼓励



明尼苏达大学最新研究颠覆认知:训练AI大模型,只需动其中一层就够了?
这项来自明尼苏达大学等机构的研究发现,大语言模型在强化学习后训练中,只需训练中间少数几层即可匹配甚至超越全参数训练效果,且这一规律跨模型、跨任务高度稳定,为更高效的AI训练策略提供了新思路。


台湾大学与NVIDIA揭秘:你的声音正在悄悄改变AI对你的判断
本文介绍VIBE框架,一套通过开放式任务评估大型音频语言模型声音诱发偏见的系统,测试12个模型后发现每个模型均存在显著性别或口音偏见。
2020
11/10
10:17
分享
点赞

边缘智算筑基、全栈软硬协同,研华科技将AI带进产业闭环
千问AI眼镜将升级为智能体眼镜:能灵活调用Skill和Agent,能全天候感知
对话Moonix郭于晨:先让用户戴上“眼镜”,再让“AI”记录世界
亮相WAIC 2026,临床实证赋能康养升级 无芯科技定义AI疗愈新范式
生态覆盖持续扩散,一文看懂各行业企业鸿蒙化转型进度
WAIC亮出集群协作真功夫,优艾智合领跑工业具身智能规模化
脑部植入物助瘫痪男子重获进食与饮水能力
能源公司IPO融资创21世纪新高,押注AI基础设施热潮
Apple Intelligence获中国监管批准,携手阿里巴巴与百度正式进入中国市场
Moonshot即将发布的Kimi K3有望赶超Anthropic Opus 4.8
OpenAI 为何开始卖 ChatGPT 品牌篮球?
DoorDash推出命令行工具,开发者可借助AI智能体直接下单
