
Check Point:“后疫情”时代仍需警惕网络钓鱼攻击
最近几周,我国新冠疫情被有效遏制、整体局面持续向好。各地全面复工、复课的喜讯不断传来,人们的生活也在渐渐回到正常轨道。然而值得关注的是,疫情期间大行其道的网络威胁并未平。近日,Check Point安全专家揭示了近几周“新冠”相关的三大网络攻击趋势:新型网络钓鱼活动冒充世卫组织和热门会议平台窃取敏感信息;最近三周平均每周发现 19.2 万起与新冠病毒相关的网络攻击,比前几周增加了30%;在过去三周内,新注册的新冠病毒相关域名接近 2 万个,其中 17% 的域名为恶意或可疑域名。

在很多普通用户、甚至网络安全从业者的思考中,钓鱼邮件或假冒网站早已被归类为技术含量低、或已经“过时”的网络攻击手段。然而,网络世界中正在发生的现实却与这些“假设”大相径庭。仅在 4 月中旬,谷歌报告称,短短一周内,每天仅通过 Gmail 发送的与新冠病毒相关的恶意软件和网络钓鱼电子邮件就超过 1,800 万,此外,每天还有 2.4 亿封与新冠病毒相关的垃圾邮件。《Verizons 2019 年数据泄露调查报告》显示,32% 的企业数据泄露的罪魁祸首是网络钓鱼电子邮件。此外,78% 的网络间谍活动都使用了网络钓鱼。因此,毫无疑问,犯罪分子将继续利用人们对新冠疫情的高度关注,冒充世界卫生组织 (WHO)、Zoom、微软或谷歌等知名组织和公司,诱骗用户提供敏感信息。
幕后黑手不断进化
Check Point安全专家发现,最近有网络犯罪分子冒充世界卫生组织从域名“who.int”发送恶意电子邮件,利用“世卫组织紧急函件:首次新冠病毒疫苗人体试验/结果最新消息”这一主题来诱骗受害者。电子邮件中包含一个名为“xerox_scan_covid-19_urgent information letter.xlxs.exe”的文件,该文件含有 AgentTesla 恶意软件。只要受害者点击该文件,该恶意软件就会自动下载。
同时,Check Point还发现了下面两种勒索电子邮件冒充联合国和世卫组织,要求将捐款转到几个已知受感染的比特币钱包,如下所示:
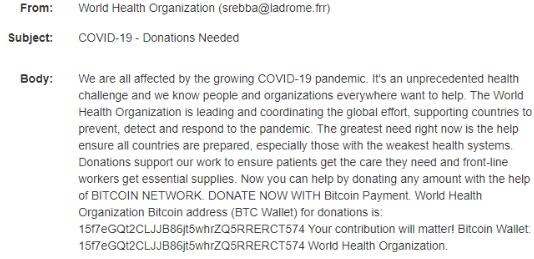

冒充视频会议应用
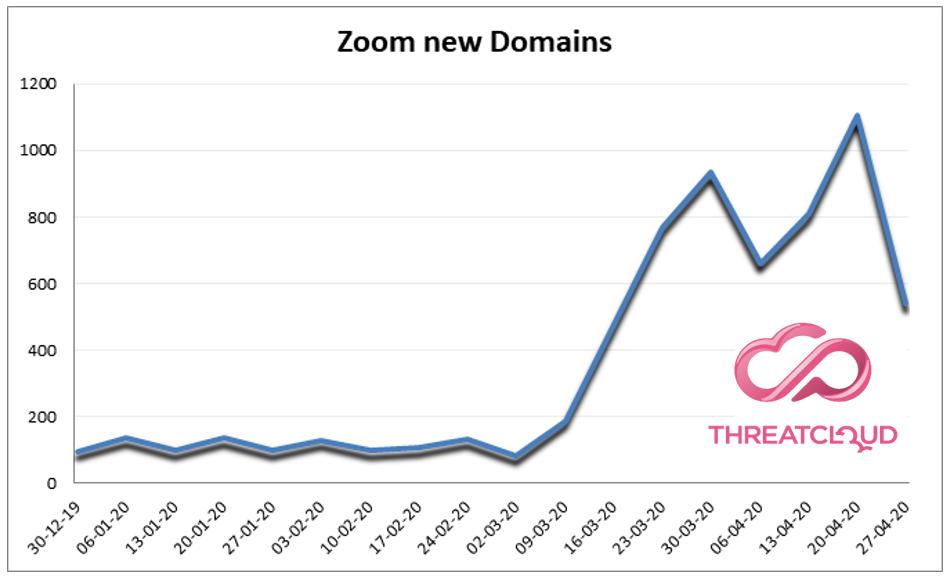
疫情期间,大多数人都在家办公时,Check Point曾报道过网络犯罪分子如何利用虚假的 Zoom 域名实施网络钓鱼活动。实际上,仅在过去三周内,与 Zoom 相关的新域名就注册了约 2,500 个(2,449 个)。1.5%(32 个)的域名是恶意域名,其他 13%(320 个)的域名是可疑域名。自 2020 年 1 月至今,全球共注册了 6,576 个与 Zoom 相关的域名。
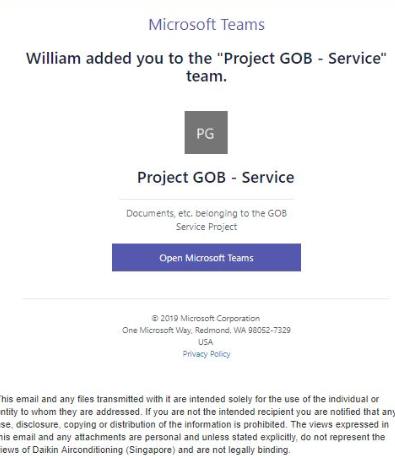
除了冒充 Zoom 之外,网络犯罪分子还使用 Microsoft Teams 和 Google Meet 来诱骗受害者。最近,以“您已被添加到 Microsoft Teams 中的团队”为主题的网络钓鱼电子邮件让很多人上当受骗。该电子邮件含有恶意网址“http://login\.microsoftonline.com-common-oauth2-eezylnrb\.medyacam\.com/common/oauth2/”,受害者只要点击打开指向该网址的“打开 Microsoft Teams”图标,恶意软件就会自动下载。而 Microsoft Teams 的实际链接为“https://teams.microsoft.com/l/team”。
与新冠病毒相关的网络攻击仍在增加
在过去三周内,每周发生的新冠病毒相关攻击多达 19.2 万起,比前几周增加了 30%。Check Point将涉及以下内容的攻击定义为新冠病毒相关攻击:域名中带有“corona”/”covid”的网站;采用“Corona”相关文件名的文件;采用与新冠病毒相关的电子邮件主题分发的文件。
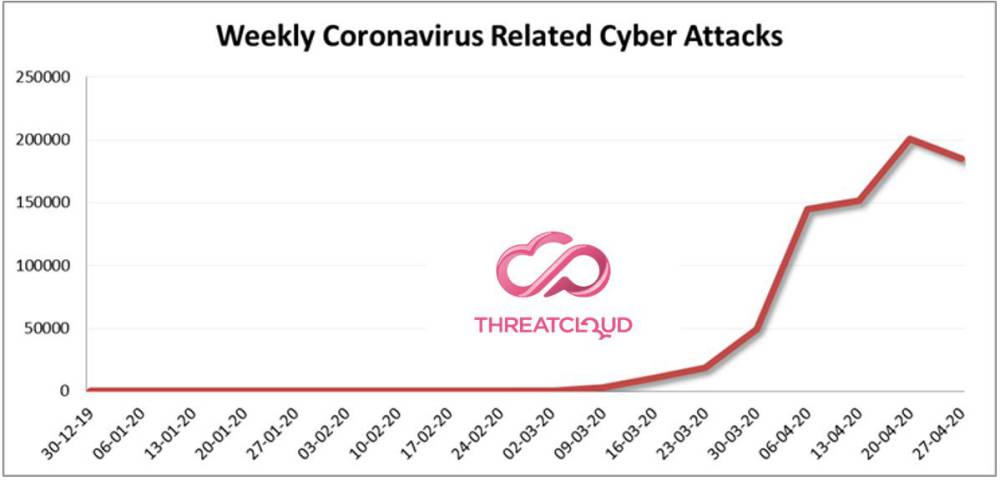
该图显示了 Check Point 通过威胁防护技术在网络、端点和移动设备中检测到的,并在全球最强大的威胁情报数据库 ThreatCloud 中进行存储和分析的所有新冠病毒相关攻击。
防范与新冠病毒相关的网络钓鱼攻击
为确保网络钓鱼攻击成功,不法分子必须通过伪装欺骗用户。为免遭攻击,如果熟悉的品牌或组织机构向您发送任何电子邮件或通信,要求您点击链接或打开附件,无论其内容看起来有多正式,都要时刻保持警惕。合法的电子邮件绝对不会要求您进行这些操作。
下面五条来自Check Point安全团队黄金法则可帮助用户确保数据安全:
- 当心相似域名、电子邮件或网站中的拼写错误以及不熟悉的电子邮件发件人;
- 谨慎打开未知发件人通过电子邮件发送的文件,尤其是当其提示您执行某些通常不会执行的操作时;
- 确保产品订购网站的真实性。有一种方法是,不要点击电子邮件中的促销链接,而是从网上搜索相应的商家,从搜索结果页面中点击商家链接。
- 谨防“特价”优惠。“仅需 499元即可获得新冠病毒独家疗法”通常不可靠或不可信。目前尚无治愈新冠病毒的有效疗法,即使可以治愈,也绝对不会通过电子邮件提供给您。
- 确保不要在不同的应用和帐户之间重复使用密码。
此外,组织应使用端到端的网络架构来阻止零日攻击,以拦截欺诈钓鱼网站并实时提供密码重用警告。Check Point Infinity 是一个有效的安全平台,它不仅涵盖所有攻击面和攻击途径,而且能提供高级防护来抵御最复杂的零日钓鱼攻击和帐户接管攻击
来源:业界供稿
好文章,需要你的鼓励



明尼苏达大学最新研究颠覆认知:训练AI大模型,只需动其中一层就够了?
这项来自明尼苏达大学等机构的研究发现,大语言模型在强化学习后训练中,只需训练中间少数几层即可匹配甚至超越全参数训练效果,且这一规律跨模型、跨任务高度稳定,为更高效的AI训练策略提供了新思路。


台湾大学与NVIDIA揭秘:你的声音正在悄悄改变AI对你的判断
本文介绍VIBE框架,一套通过开放式任务评估大型音频语言模型声音诱发偏见的系统,测试12个模型后发现每个模型均存在显著性别或口音偏见。
2020
05/27
17:23
分享
点赞

边缘智算筑基、全栈软硬协同,研华科技将AI带进产业闭环
千问AI眼镜将升级为智能体眼镜:能灵活调用Skill和Agent,能全天候感知
对话Moonix郭于晨:先让用户戴上“眼镜”,再让“AI”记录世界
亮相WAIC 2026,临床实证赋能康养升级 无芯科技定义AI疗愈新范式
生态覆盖持续扩散,一文看懂各行业企业鸿蒙化转型进度
WAIC亮出集群协作真功夫,优艾智合领跑工业具身智能规模化
脑部植入物助瘫痪男子重获进食与饮水能力
能源公司IPO融资创21世纪新高,押注AI基础设施热潮
Apple Intelligence获中国监管批准,携手阿里巴巴与百度正式进入中国市场
Moonshot即将发布的Kimi K3有望赶超Anthropic Opus 4.8
OpenAI 为何开始卖 ChatGPT 品牌篮球?
DoorDash推出命令行工具,开发者可借助AI智能体直接下单
Check Point:以AI技术赋能云端交付平台化安全解决方案
Check Point 推出全新 SaaS 威胁防御解决方案
Check Point:2024年,企业应积极推进行云安全变革
Check Point推出 ThreatCloud Graph:从多维视角评估网络安全态势
Check Point:网络安全发展历史大事记
Check Point+七云网络 强强共建SD-WAN安全
沃尔玛成为 2023 年第三季度网络钓鱼诈骗中最常被冒充的品牌
服务出海 Check Point全面防御内外威胁
Check Point 软件技术公司通过全新安全托管功能增强了 Infinity 全球服务
Check Point Software 第三季度业绩超预期
