

Nvidia全面推出DGX Cloud平台 可即时访问生成式AI基础设施
Nvidia今天宣布广泛推出下一代DGX超级计算平台Nvidia DGX Cloud,使企业能够访问Oracle Cloud Infrastructure及其云服务上的数千个GPU。

有意见 | CPU、GPU和服务器都要增强自主创新啦!
工信部信息通信发展司司长谢存表示,将增强自主创新能力,加强CPU、GPU和服务器等重点产品研发,加速新技术、新产品落地应用
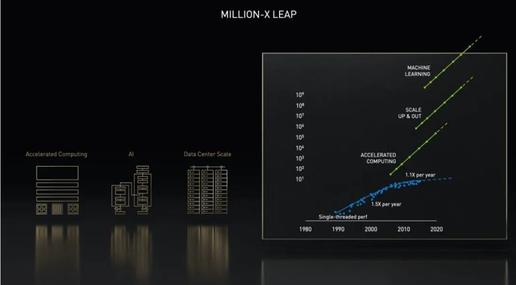
【百万倍加速】加速计算重新定义药物研发
我们将通过《NVIDIA 加速计算,百万倍加速行业应用》系列文章,为您详解 NVIDIA 如何通过数据中心规模的全栈加速计算,助力多个行业实现百万倍计算性能飞跃,高效解决人类挑战。


英伟达首席技术官Michael Kagan专访
英伟达正积极拥抱一种新的计算范式,利用大规模并行计算机系统为新一代应用程序提供服务。而这场变化的开端,主要始于以色列。
智慧渲染,通用为“先” 象帝先推动 “通用、好用、高性能、自主可控” GPU解决方案
针对不同应用场景,象帝先GPU发挥通用赋能优势,与各种系统配合的成熟度较高,从而提升企业用户的生产效率。


AMD这一把算是把AI玩明白了
自2017年AMD回归数据中心处理器,到去年已经提供了第四代AMD EPYC(霄龙)处理器,帮助云、企业和高性能计算等关键应用负载。今年,AMD首席执行官苏姿丰(Lisa Su)也没有让我们失望,抢先带来了包括CPU和GPU在内的一系列更新。

英特尔宣布放弃CPU-GPU引擎,转而将NNP引入GPU
最近于汉堡举行的ISC23超级计算大会上,英特尔再次阐明了对于Falcon Shores的规划,确认该设备就是纯GPU计算引擎,而且目前发布混合XPU的时机还不成熟。

英特尔称AI已主导CPU、GPU乃至云设施,因此Meteor Lakes将全系配备VPU
Movidius技术已在第13代酷睿芯片中有所应用,并将成为下一代消费级芯片的主流配置。
英特尔放弃将CPU、GPU与内存纳入同一封装的XPU开发计划
英特尔曾发下宏愿,立场将CPU、GPU和内存芯片塞进统一的XPU封装当中。但如今,这个目标已然宣告失败。

英伟达GPU的生命循环——产自晶圆厂,又用于晶圆厂
台积电、ASML和Synopsys都在使用英伟达加速器来加速或支持计算光刻技术。与此同时,KLA Group、Applied Materials和日立也在英伟达的并行处理芯片上运行深度学习代码,借此进行电子束与光学晶圆检测。

把握历史性时刻,谷歌决意投资GPU计算
在一年前的谷歌I/O 2022大会上,谷歌向全世界展示了其内部机器学习中心使用的8-pod TPUv4加速器,包含总计32768个第四代原研矩阵数学加速器。


窥见未来:英伟达AI推理的前进之路
在英伟达,负责引导研究朝着应用、而非纯学术项目前进的,是斯坦福大学计算机科学与电气工程兼职教授,公司首席科学家、高级研究副总裁以及GPU、网络与CPU芯片设计师Bill Dally。
分析:Nvidia在公有云中保持强劲的增长势头
Nvidia的GPU是业内最常见、最强大的。除了硬件之外,NVIDIA还通过软件工具推进Nvidia的普及,这些软件工具涵盖了从边缘推理到自动驾驶再到医学成像的各个领域,潜力无限。

微软发布最新AI优化的Azure实例
微软公司Azure高性能计算和人工智能群组首席项目经理Matt Vegas在博客文章中写道:“为我们的客户兑现高级人工智能的承诺,这需要超级计算基础设施、服务和专业知识,以应对呈指数级增长的规模和最新模型的复杂性。

摩尔线程为“完美体验”持续进化 加速云桌面产品生态共建
GPU创业是一个长期事业,充满了挑战,我们深知生态的重要性。我们只有与生态伙伴、行业用户凝聚在一起,才能将摩尔线程的算力真正发挥出来。

加速视频解码与转码性能 中科大洋展示英特尔数据中心GPU Flex 140创新应用成果
在近日举行的“应云而变,携手加速创新”为主题的英特尔数据中心GPU Flex系列媒体沟通会上,中科大洋技术研究院院长褚震宇分享了英特尔GPU在视频解码与转码方面的创新实践。
