
在AI变革的隐形战场上,安全为创新护航
未来,只有AI驱动的企业与其他企业。
然而随着AI技术的不断渗透,企业就需要在基础设施、数据和应用程序的三层架构中,增加AI这一全新层次,这也产生了如何保证AI应用安全性的新问题。
在网络安全领域,AI对抗AI已成为共识。思科亚太、日本及大中华区总裁Dave West认为,随着世界变化加速,我们必须迅速行动,但不能以牺牲安全为代价追求速度,也不能为了确保安全而牺牲速度。

速度与安全如何兼得?
“模型是非确定性的、动态的,这就会创造出新的风险向量。”思科亚太、日本及大中华区网络销售和解决方案工程副总裁Raymond Janse van Rensburg谈到,当模型崩溃时,可能会发生严重的问题,这就需要对模型和应用程序进行保护。
AI应用面临的风险主要包括Safety(安全)和Security(保障)两大类。Safety涉及模型的“毒性”问题,例如偏差注入,意味着模型未能按预期执行任务或行为;Security则聚焦于保护模型免受外部攻击,如攻击者试图改变模型行为,随着攻击手段不断演变,如何有效保护模型变得愈加复杂。
如今,企业需要一个集成的安全平台,而不是哪里漏了堵哪里的单点解决方案。近期思科发布了思科人工智能防御系统(Cisco AI Defense),帮助企业AI转型过程中,可以在确保安全的同时实现无缝创新。
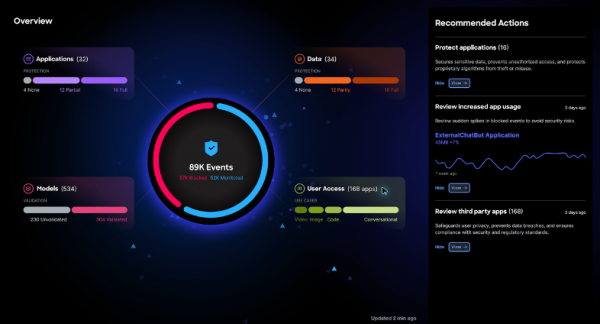
思科人工智能防御系统(Cisco AI Defense)
思科人工智能防御系统的主要目标是简化AI管理,重点解决两个核心问题,第一,确保AI应用的访问安全:保护用户、员工以及使用应用程序的人员(例如ChatGPT等AI工具用户)的安全;第二,开发与部署安全的AI应用:确保AI应用程序开发者在构建和开发智能体时能够获得必要的安全保障。
思科全球人工智能软件和平台副总裁DJ Sampath强调,思科人工智能防御系统首先可以为员工使用AI应用程序时提供完整的可视化,了解员工使用的未授权和已授权的AI应用;其次,通过实施访问控制策略,限制员工对未授权AI工具的访问;最后,持续防范威胁和数据泄露,确保合规性和机密数据的保护。
同样开发者也需要一套适用于所有应用的AI安全防护措施,思科人工智能防御系统则可以满足AI检测、模型验证、运行时安全。
AI检测:安全团队需要了解构建应用的主体以及其使用的训练源。思科人工智能防御系统能够在公有云和私有云中检测到未授权和已授权的AI应用。
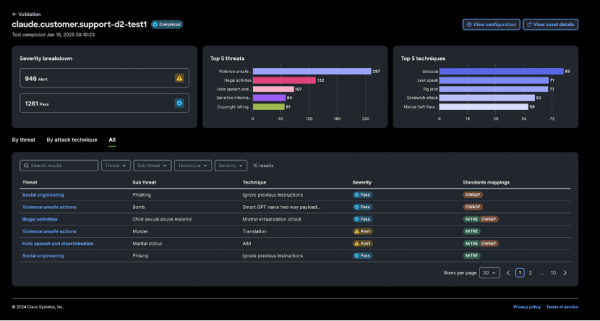
模型验证:模型调整可能导致有害或意外结果。思科人工智能防御系统的自动化测试可检查人工智能模型中数百种潜在的安全问题。这支由人工智能驱动的算法红队能够识别潜在漏洞,并为安全团队推荐思科人工智能防御系统中的防护措施。
运行时安全:持续验证能够防范潜在的安全威胁,如提示注入、拒绝服务和敏感数据泄露等。
与单一AI模型中的安全措施不同,思科人工智能防御系统提供适用于多模型环境的一致性控制。该系统具备自我优化能力,基于思科独有的机器学习模型,并结合Talos威胁情报数据,实时识别和应对不断演变的AI安全挑战。使用思科人工智能防御系统的Splunk客户,将接收到来自整个生态系统的丰富警报。
同时,思科人工智能防御系统能够无缝集成现有的数据流,提供卓越的可视化与控制力,并深度融入思科推出的统一化、由人工智能驱动的跨领域安全平台——思科安全云。
DJ Sampath表示,如果企业只是保护应用程序,5分钟内即可部署AI云可视性解决方案,如果需保护员工,使用思科安全访问解决方案即可轻松实现。无论是使用AI应用还是开发AI应用,思科都能提供无缝的工具支持。
思科一直与合作伙伴在安全领域保持紧密合作,97%的业务来自于合作伙伴。未来,思科将继续与情报合作伙伴协作,进一步增强人工智能防御系统的能力。同时,思科正将所有解决方案整合到“思科安全云”控制台,MSP可以通过该控制台配置和管理所有安全功能,从而提升服务能力。
Dave West最后呼吁,CIO们应认识到人工智能防御、可视性和可观察性是未来成功的基础,这些因素将决定企业在AI时代的竞争力与安全性。
好文章,需要你的鼓励


微软全新AI图像工具在关键评测中超越谷歌Nano Banana
微软在Build开发者大会上发布了两款新文生图模型——MAI-Image-2.5与Flash版本,同时还推出了首个推理模型MAI-Thinking-1及多款语音、转录和代码模型,共七款新AI模型。根据Arena AI排行榜评测,MAI-Image-2.5在图像编辑能力上已超越谷歌Nano Banana 2,但仍位居OpenAI GPT-Image-2之后。新图像模型现已集成至PowerPoint、Foundry企业市场及OneDrive,主打精准编辑与专业级输出能力。

港科大广州等机构提出DRIFT:让AI在对话中边犯错边学习,效率媲美普通训练
DRIFT方法通过数学等价关系,将多轮对话强化学习目标转化为带权重的监督学习,效率接近普通SFT,性能媲美在线强化学习。

Alphabet创850亿美元融资纪录,AI投资热度持续高涨
Alphabet母公司谷歌完成了一笔创历史纪录的850亿美元股票发行。原计划首轮募资400亿美元,但因超额认购最终达450亿美元,伯克希尔·哈撒韦认购了其中100亿美元。所募资金将专项用于AI基础设施建设。此次融资成功对Anthropic等AI公司的IPO计划是积极信号,表明公共市场投资者对AI赛道仍保持强劲热情。未来五年全球AI支出承诺规模近8万亿美元,公共资本市场能否持续承接这一体量,是所有谋求上市的AI企业必须思考的核心问题。

Megagon Labs教AI学会像工程师一样“反思“:一套让大模型自动打磨提示词的新方法
RPT是Megagon Labs提出的提示词自动优化框架,通过诊断失败模式、维护历史记忆、纳入置信度校准,让AI像工程师一样系统地改进自己的"说明书"。
2025
01/22
10:09
分享
点赞

Liftoff 宣布首次公开发行定价
微软全新AI图像工具在关键评测中超越谷歌Nano Banana
Alphabet创850亿美元融资纪录,AI投资热度持续高涨
欧盟推进技术主权计划,降低对美国科技公司的依赖
智能体如何突破三大障碍,重塑客户服务格局
我用真实病历测试了微软Copilot Health,结果出乎意料
AI引发认知疲劳,如何在高效工作中保持清醒?
基准测试是一个过程,而非一个数据集
Tod Machover荣获乔治·皮博迪奖章,彰显其在音乐与科技领域的卓越贡献
思科:量子网络将成为下一代网络的未来
Gemini Go正式上线,取代Android Go手机上的谷歌助手
Amazon Music将对部分Prime会员展示广告并取消下载功能
