
Knightscope的自主安全机器人为公共安全提供突破性检测技术
高密度电源模块助力敏锐的监控网络利用 AI 震慑犯罪
自动警务的概念始于几年前的科幻小说,但今天却是真实存在的,而且很有影响力。如果您花几分钟时间与Knightscope 公司的联合创始人、首席客户官 Stacy Stephens 聊聊,就会发现先进的机器人安保其实更具吸引力。
这家公共安全技术服务公司于 2013 年在加州山景城成立,是世界上第一家在大型购物中心、停车场和社区公园等公共场所部署移动、全自主安全机器人 (ASR) 的公司。Knightscope 的愿景是找到更有效的方法遏制犯罪,同时最大限度降低执法人员面临的危险。

Knightscope 的移动机器人是完全自主的,使用支持激光雷达、GPS、声纳、IMU、4K 摄像头以及高保真音频的系统。该机器人有五种类型的传感器 — 与人类非常相似,但灵敏度远远高于人类。
Knightscope 是一家领先的公共安全技术公司,而并非一家在机器人技术、自动驾驶技术、汽车电气化和人工智能融合方面有专长的机器人技术企业。但将以上结合起来,他们带来了一个敏捷的平台,该平台可整合众多传感功能和其它技术,以提供可执行的情报。
提供卓越的 ASR 监视功能
配备 ASR,主要是为了扫描已知威胁,使企业能通过识别被解雇的员工或发放了非法侵入警告的员工来减少工作场所暴力。此外,ASR 还可使用异常监控来识别外部车辆的车牌,从而保障停车场安全。ASR 可凭借其音频特性提供双向通信,允许机器人作为具有广播功能的公共广播系统。因此它们可以与肇事者接触,缓和敌对情况。
“ASR 的‘通话’功能可将危险从人转移到机器人身上。”Stephens 指出,“机器人是一种难以描述的物体,进行对话无需有人站在敌对嫌疑人面前,这可避免事态无意中升级。”“此外,它们还可降低运营开销。”Stephens 补充道,“ASR 既不会生病,也不需要休假。”
注入技术,驱动 ASR 的自主性
Knightscope 的移动机器人是完全自主的,使用支持激光雷达、GPS、声纳、IMU、4K 摄像头以及高保真音频的系统。该机器人有五种类型的传感器(与人类类似),周围环境尽在掌握。大多数情况下,该机器人的感官比公共安全人员还敏锐。
总共有 21 个 LIDAR 激光器,每 25 毫秒绘制一次四周环境。这些数据用于创建机器人周围 100 米半径区域的 3D 地图,可帮助 ASR“看到”其周围环境。此外,声纳传感器还可提供接近感测,使机器人能够判断什么时候有什么物体靠近。GPS 是内部导航的第三输入,如果有人试图移动或偷窃机器人,有助于对其进行跟踪。
里程计传感器通过计算车轮的旋转指示机器人向左还是向右移动或跟踪。最后是惯性测量单元 (IMU),可提供六个自由度的空间感知,以确定机器人是直立还是倾斜的,这可能说明它已经卡住或无法移动。
电源效率对于 ASR 极为重要
高强度的计算、通信和传感为 ASR 的供电网络带来沉重负担。它们必须紧凑、高效。ASR 没有气流或通风功能,因此 Knightscope 开始寻找一种可使用铝皮作为散热片的单纯传导散热解决方案。该公司采用了 Vicor DC-DC 转换器模块 (DCM3623),因为其独特的 ChiP™ 封装不仅散热良好,而且外形极为小巧。此外,该 DCM 的功率密度还为布线和线缆组合提供了帮助,并提高了电池效率和性能,延长了运行时间。
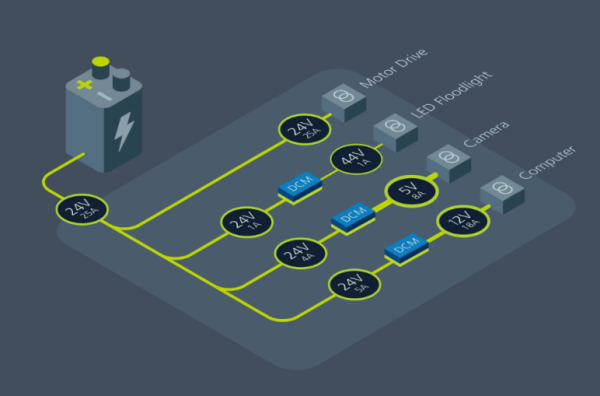
典型的移动机器人应用可为各种负载供电,从计算机到电机驱动器,再到摄像头,不一而足。Knightscope 不仅支持 LIDAR、GPS、声纳、IMU、4K 摄像头和高保真音频,而且还使用 Vicor 高密度电源模块为这些负载供电。Knightscope 寻求紧凑而高效的电源,因为 ASR 没有气流或散热功能。他们需要一种可使用铝皮作为散热片的单纯传导散热解决方案。
在电气方面,机器人需要与所有不同的电源轨隔离。由于有太多具有不同 EMI 特征的传感器,Vicor DCM™ 有助于最大限度减少 EMI 和噪声干扰。
“我们越能减轻电池负担,所获得的运行时间就会越长。”Stephens 表示,“所以,电源永远都是一个考虑因素。最后,所有这些都将帮助我们实现公司的愿景,即架构师坐下来规划商业开发或混合使用的空间时,与烟感报警器及灭火系统一样,我们的产品都会列入安全检查清单。”
镇上似乎来了一位新警长啊,它的名字叫 Knightscope。
来源:业界供稿
好文章,需要你的鼓励


IT部门面临的十大挑战与应对策略
CIO们正面临众多复杂挑战,其多样性值得关注。除了企业安全和成本控制等传统问题,人工智能快速发展和地缘政治环境正在颠覆常规业务模式。主要挑战包括:AI技术快速演进、IT部门AI应用、AI网络攻击威胁、AIOps智能运维、快速实现价值、地缘政治影响、成本控制、人才短缺、安全风险管理以及未来准备等十个方面。

北航团队发布AnimaX:让静态3D模型瞬间“活“起来的神奇技术
北航团队发布AnimaX技术,能够根据文字描述让静态3D模型自动生成动画。该系统支持人形角色、动物、家具等各类模型,仅需6分钟即可完成高质量动画生成,效率远超传统方法。通过多视角视频-姿态联合扩散模型,AnimaX有效结合了视频AI的运动理解能力与骨骼动画的精确控制,在16万动画序列数据集上训练后展现出卓越性能。

CIO放弃散弹枪式做法,采用更具战略性的AI试点
过去两年间,许多组织启动了大量AI概念验证项目,但失败率高且投资回报率令人失望。如今出现新趋势,组织开始重新评估AI实验的撒网策略。IT观察者发现,许多组织正在减少AI概念验证项目数量,IT领导转向商业AI工具,专注于有限的战略性目标用例。专家表示,组织正从大规模实验转向更专注、结果导向的AI部署,优先考虑能深度融入运营工作流程并产生可衡量结果的少数用例。

让AI看图说话更详细更准确:上海人工智能实验室团队开发的ScaleCap技术突破
这项研究解决了AI图片描述中的两大难题:描述不平衡和内容虚构。通过创新的"侦探式追问"方法,让AI能生成更详细准确的图片描述,显著提升了多个AI系统的性能表现,为无障碍技术、教育、电商等领域带来实用价值。
2023
04/06
09:57
分享
点赞

IT部门面临的十大挑战与应对策略
CIO放弃散弹枪式做法,采用更具战略性的AI试点
CISO如何成为3090亿美元AI基础设施支出的守门人
PNG图像标准第三版发布,新增EXIF支持
Threads推出独立隐藏词汇管理功能并支持时限设置
论文有多水?这个AI系统一眼识破:KnoVo自动评估学术论文创新值
企业智能体扩展面临的隐形挑战与解决方案
Salesforce首席执行官:AI已承担公司近半数工作
谷歌推出AI虚拟试衣应用Doppl,让你可视化穿搭效果
超大规模运营商将在2030年前占据全球数据中心容量60%
AI初创工作室计划每年推出十万家公司
OpenDylan 2025.1版本发布:抛弃括号的Lisp语言获得重要更新
