
全球IPv6峰会丨新华三提出IPv6+规模化部署的六大能力支撑
9月9日,全球IPv6峰会如期举行,本次会议汇聚全球顶尖产业专家,分享行业动态、探讨前沿趋势和应用部署,共研IPv6下一代互联网新技术、新生态。紫光股份旗下新华三集团受邀出席,并从IPv6发展趋势洞察、行业应用、技术落地和安全管理多方面介绍了新华三在推动IPv6下一代互联网发展的最新探索与实践。
新华三提出IPv6+规模化部署应当具备的六大能力
数字经济已成为中国经济发展的重要引擎,其中下一代网络发展至关重要。2022年初,国务院发布《“十四五”数字经济发展规划》,再次强调要推动IPv6规模部署,助力信息网络基础设施升级。IPv6已经从单纯的互联网技术上升到国家战略层面,随着各种政策的下发,IPv6迎来了全面部署期。除此之外,各种产业的数字化升级也带来了新需求。5G、物联网、高清视频、元宇宙等新业务对网络提出了更高的要求,而算网融合、分支协同、远程办公等新模式的出现同样要求网络能够提供支撑。这些都对网络的灵活敏捷、高效部署、安全可靠提出了更高要求。
IPv6+不是某一个协议或者某一种组网,而是基于IPv6头部的可扩展性衍生出的一系列技术创新和场景创新,作为数智化网络建设的基石,它需要具备以下六大维度的能力:超宽、极简、确定性、融合、智能、可信。因此,新华三集团的IPv6+智能联接方案也由此侧重展开。

技术突破+应用落地+内生安全,新华三助力构建IPv6+智能联接
新华三集团侧重分享了前沿技术探索、行业应用和安全管理这三个方面的实践。
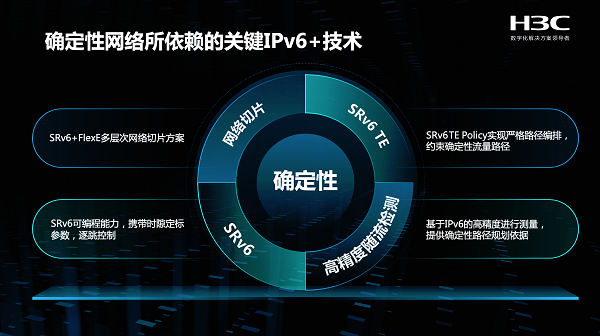
在前沿技术探索方面,新华三重点分享了基于IPv6+技术在确定性广域网的应用与探索。随着智能工厂、远程医疗、无人驾驶等新兴应用的出现,对网络提出了更高的要求。为了满足这些新兴的远程应用环境,在新华三确定性广域网实现中,大量使用了IPv6+的新技术。
● 其一,基于SRv6 TE Policy的严格转发路径约束技术,通过它实现确定性流量的路径独立;
● 其二,借助SRv6+FlexE的多层次切片能力,为确定性应用分配一个独立的平面保障带宽,从而保证确定性流量的较小丢包率;
● 其三,使用基于IPv6的高精度随流检测技术来进行路径链路时延测量与标定,为确定性路径提供纳秒级精度的测量结果,大幅提高了确定性时延的保障效果;
● 其四,在承载协议上选择了可编程的SRv6技术,充分利用SRv6的灵活可编程能力,实现时隙映射信息的携带,保障每一个转发节点都能按照预设的时隙要求传送确定性报文。
在行业应用方面,新华三集团坚持应用驱动的理念,以不同行业的业务需求作为技术创新的基础,提供细分的场景化方案。以新一代SRv6电子政务外网解决方案为例,该方案具备“一网承载、云网融合”,“网安联动、主动安全”以及“AI加持、智能运维”的特点。其中一个特点,部署基于SRv6 Policy的SDN骨干网,实现自动负载均衡,提升链路利用率;实现按业务需求自动选择最优路径,实时保障关键业务质量;实现一跳入云,业务分钟级开通。部署多张网络切片,整合多张专网政务应用,实现专片专享业务隔离,切片业务互不干扰。除此之外,新华三在运营商、金融、高校、大型企业等行业积极推动IPv6建设,为客户筑牢数字经济时代的坚实底座。

在网络安全方面,IPv6新协议架构也将带来安全领域的技术创新和体系架构变革,从而为解决IPv6+时代的网络安全问题提供新思路、新方法和新手段。新华三基于IPv6+内置安全属性和安全技术创新来构建适用于IPv6+时代的网络安全体系,并提出了“四维一体” IPv6+网络内生安全体系,从感知维解决应用洞察和全栈可视,从分析维解决场景认知和数据赋能,从控制维解决精准运营和策略管控,从响应维解决自主构建,敏捷响应。

作为下一代网络技术发展的核心推动者,新华三集团将持续依托对IPv6行业的前瞻洞察及全栈创新能力,携手行业伙伴共同推动IPv6产业加速发展,不断深化IPv6在各行业的应用创新,助力中国数字经济发展。
来源:业界供稿
好文章,需要你的鼓励


拆解视频大语言模型评测基准:知识、空间感知还是真正的时序理解?苹果公司研究团队带来新分析框架
这项来自苹果公司的研究揭示了视频大语言模型评测的两大关键问题:许多测试问题不看视频就能回答正确,且打乱视频帧顺序后模型表现几乎不变。研究提出VBenchComp框架,将视频问题分为四类:语言模型可回答型、语义型、时序型和其他类型,发现在主流评测中高达70%的问题实际上未测试真正的视频理解能力。通过重新评估现有模型,研究团队证明单一总分可能掩盖关键能力差距,并提出了更高效的评测方法,为未来视频AI评测提供了新方向。

差分信息:一种信息论视角下理解偏好优化的新方法 - KAIST AI研究团队突破性解读
这篇来自KAIST AI研究团队的论文提出了"差分信息分布"(DID)这一创新概念,为理解直接偏好优化(DPO)提供全新视角。研究证明,当偏好数据编码了从参考策略到目标策略所需的差分信息时,DPO中的对数比率奖励形式是唯一最优的。通过分析DID熵,研究解释了对数似然位移现象,并发现高熵DID有利于通用指令跟随,而低熵DID适合知识密集型问答。这一框架统一了对DPO目标、偏好数据结构和策略行为的理解,为语言模型对齐提供理论支持。

VidText:视频文本理解的全面评估新基准,打造视觉文本与上下文交互的研究新高度
VidText是一个全新的视频文本理解基准,解决了现有评估体系的关键缺口。它涵盖多种现实场景和多语言内容,提出三层评估框架(视频级、片段级、实例级),并配对感知与推理任务。对18个先进多模态模型的测试显示,即使最佳表现的Gemini 1.5 Pro也仅达46.8%平均分,远低于人类水平。研究揭示输入分辨率、OCR能力等内在因素和辅助信息、思维链推理等外部因素对性能有显著影响,为未来视频文本理解研究提供了方向。

ZeroGUI:零人工成本下自动化在线GUI学习的突破性研究
ZeroGUI是一项突破性研究,实现了零人工成本下的GUI代理自动化在线学习。由上海人工智能实验室和清华大学等机构联合开发,这一框架利用视觉-语言模型自动生成训练任务并提供奖励反馈,使AI助手能够自主学习操作各种图形界面。通过两阶段强化学习策略,ZeroGUI显著提升了代理性能,在OSWorld环境中使UI-TARS和Aguvis模型分别获得14%和63%的相对改进。该研究彻底消除了传统方法对昂贵人工标注的依赖,为GUI代理技术的大规模应用铺平了道路。
2022
09/13
18:14
分享
点赞

IXD0579M高压侧和低压侧栅极驱动器提供紧凑型即插即用解决方案
向下扎根求力量,向上迸发促未来|2025 友达数位智能制造年度峰会圆满落幕!
新一代Dell PowerEdge机架式服务器助力数据中心加速进化
站在下一次浪潮的最前沿,微软眼中的“开放智能体网络”
互联网女皇玛丽·米克尔刚发布了一份340页的《人工智能趋势报告》,这里总结了10个核心观点
吴恩达LangChain对话:别纠结Agent定义,成功的智能体往往从线性工作流开始,Vibe Coding这个概念充满误导
是否应该为 Google 的 Veo 3 支付 Gemini Ultra 费用来制作 AI 视频?我的体验告诉你答案
KO 满血版DeepSeek?AM-Thinking-V1,32B干翻一众千亿级大模型
字节Seed团队绝地翻盘,发现多模态模型也有涌现时刻,开源BAGEL模型
物理世界如何实现AGI?前空中客车CTO红杉访谈:我们的愿景是让AI设计人类无法设计的系统,从星际飞船到戴森球
法国政府正式出价4.1亿欧元收购Atos精简后的高性能计算资产
理解 GPU 服务器及其在数据中心中的角色
