
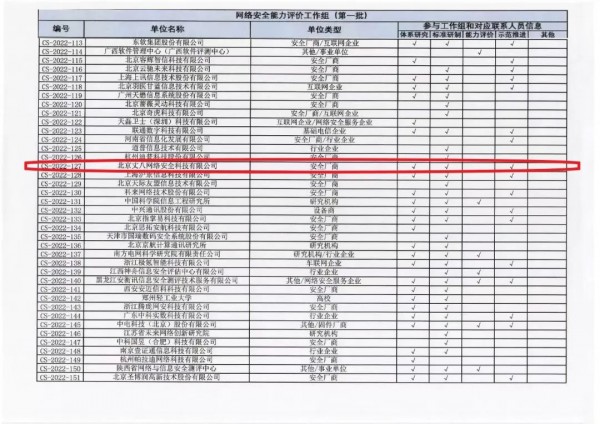
丈八网安入选信通院首批“网络安全能力评价工作组”成员单位
近日,中国信息通信研究院公布第一批“网络安全能力评价工作组”,丈八网安凭借在网络安全方面的科研实力、产品研发能力、技术创新水平、人才培养成果等综合素质,成为第一批工作组成员单位,参与体系研究、标准研制、示范推进三大子工作组的能力评价工作当中。
此前,中国信通院安全研究所开展的“先进网络安全能力验证评估计划(第七期)网络空间资产平台能力评测”中,丈八网安有幸作为技术支撑单位,参与本次评测的协助工作。在本次项目中,通过公司自研产品“火天”系列产品“火天网测™”测试床平台和全新定义的“Meta Computing”技术相结合为评测过程提供支撑。
近期,丈八网安将作为牵头单位,基于在网络靶场及仿真应用领域的深耕成果,结合国内外市场发展情况、技术发展现状与趋势的理解,辅以科学的分析方法,联合国内靶场领域厂商,共同进行“网络安全产品能力评价体系”中网络空间靶场平台相关标准的制定。
为深入贯彻习近平总书记关于发展网络安全产业的重要指示精神,落实《中华人民共和国网络安全法》《中华人民共和国国民经济和社会发展第十四个五年计划和2035远景目标纲要》部署要求,构建网络安全能力科学评价体系,引领网络安全技术产品高质量发展,推动形成人才培养、技术创新、产业发展良性生态,中国信息通信研究院牵头成立网络安全能力评价工作组,遴选工作组成员单位。
体系研究子工作组
研究国内外网络安全能力评价体系和方法。研究网络安全产品服务类别、技术创新方向、典型应用场景和应用模式等,研究网络安全产品分类,形成清单、图谱。综合被评价方技术产品方向、评价方基础能力、评价结果应用场景等,研究网络安全产品能力评价机构管理要求。
标准研制子工作组
推进网络安全能力评价标准化工作,研制概念和指南、评价指标要求、评价指南、通用测试方法等总体指导性标准,以及主动防御、安全运营与事件响应、数据安全等细分类别网络安全产品、服务等能力评价标准。
示范推进工作组
搭建能力评价成果示范推进平台,挖掘形成细分领域网络安全产品服务卓越案例集、网络安全产品服务提供商竞争力名录等,促进释放网络安全产业基础动能。组织开展网络安全技术应用试点示范项目验证和应用推介。
丈八网安立足于网络安全相关技术研究、产品研发、人才培养及服务支撑领域,秉承让网络安全仿真及应用核心
技术掌握在国人手中的使命,长期以来在国家第五空间安全事业上勤勉深耕,构建实战化场景仿真模拟平台。我们将为使命付诸实践,不懈努力,成为中国领先的网络安全仿真及应用平台供应商,为国家构建全面网络防护体系奉献力量。
好文章,需要你的鼓励


CES上杨元庆首谈AGI,碾压人类的叙事不会让AI更聪明
很多人担心被AI取代,陷入无意义感。按照杨元庆的思路,其实无论是模型的打造者,还是模型的使用者,都不该把AI放在人的对立面。

MIT递归语言模型:突破AI上下文限制的新方法
MIT研究团队提出递归语言模型(RLM),通过将长文本存储在外部编程环境中,让AI能够编写代码来探索和分解文本,并递归调用自身处理子任务。该方法成功处理了比传统模型大两个数量级的文本长度,在多项长文本任务上显著优于现有方法,同时保持了相当的成本效率,为AI处理超长文本提供了全新解决方案。

Gmail新增Gemini驱动AI功能,智能优先级和摘要来袭
谷歌宣布对Gmail进行重大升级,全面集成Gemini AI功能,将其转变为"个人主动式收件箱助手"。新功能包括AI收件箱视图,可按优先级自动分组邮件;"帮我快速了解"功能提供邮件活动摘要;扩展"帮我写邮件"工具至所有用户;支持复杂问题查询如"我的航班何时降落"。部分功能免费提供,高级功能需付费订阅。谷歌强调用户数据安全,邮件内容不会用于训练公共AI模型。

华为研究团队突破代码修复瓶颈,8B模型击败32B巨型对手!
华为研究团队推出SWE-Lego框架,通过混合数据集、改进监督学习和测试时扩展三大创新,让8B参数AI模型在代码自动修复任务上击败32B对手。该系统在SWE-bench Verified测试中达到42.2%成功率,加上扩展技术后提升至49.6%,证明了精巧方法设计胜过简单规模扩展的技术理念。
2022
05/11
13:13
分享
点赞

联想集团混合式AI实践获权威肯定,CES期间获评“全球科技引领企业”
CES上杨元庆首谈AGI,碾压人类的叙事不会让AI更聪明
CES 2026 | 重大更新:NVIDIA DGX Spark开启“云边端”模式
Gmail新增Gemini驱动AI功能,智能优先级和摘要来袭
研究发现商业AI模型可完整还原《哈利·波特》原著内容
Razer在2026年CES展会推出全息AI伴侣项目
CES 2026:英伟达新架构亮相,AMD发布新芯片,Razer推出AI奇异产品
通过舞蹈认识LimX Dynamics的人形机器人Oli
谷歌为Gmail搜索引入AI概览功能并推出实验性AI智能收件箱
DuRoBo Krono:搭载AI助手的智能手机尺寸电子阅读器
OpenAI推出ChatGPT Health医疗问答功能
Anthropic寻求3500亿美元估值融资100亿美元
NHS 医护人员对卫生服务网络安全措施缺乏信心
薄弱的网络防御正在暴露关键基础设施的风险 - 企业如何主动防范精明的攻击者以保护我们所有人
数千个已私有化的 GitHub 代码库仍可通过 Copilot 访问
Check Point 联合创始人谈 AI、量子计算和独立性
Versa 声称重新定义企业级 SASE
告别分享个人手机号的烦恼:Surfshark 虚拟号码服务全新上线
苹果目前仅能检测出一半被感染 Pegasus 间谍软件的 iPhone
网络监测中心设立"飓风等级制"评估网络攻击损失
Deepwatch 收购安全情报公司 Dassana,加强 AI 驱动的网络安全防御能力
AI 驱动的关键基础设施网络安全创企 Dream 以 11 亿美元估值融资 1 亿美元
