
Jumio全球调研显示72%的消费者每天都担心遭受深度伪造欺骗
该项新调查还显示,消费者仍高估了自己识别深度伪造的能力,并希望政府采取更多措施来监管人工智能

美国加利福尼亚州森尼韦尔 — 2024 年 5 月 14 日 — 领先的自动化、人工智能驱动的身份验证、风险评估和合规解决方案提供商Jumio今天发布了“Jumio 2024 在线身份研究报告”,这是其年度全球消费者调研的第三部分。今年的调研结论显示出消费者对生成式人工智能和深度伪造相关风险的极大担忧,包括网络犯罪和身份欺诈增加的可能性。
该研究调查了来自英国、美国、新加坡和墨西哥的8,000多名成年消费者的观点。研究结果表明,近四分之三的消费者(72%)每天都担心被深度伪造欺骗,从而泄露敏感信息或被骗金钱。只有15%的全球消费者(新加坡只有7%)表示他们从未遇到过深度伪造的视频、音频或图像。
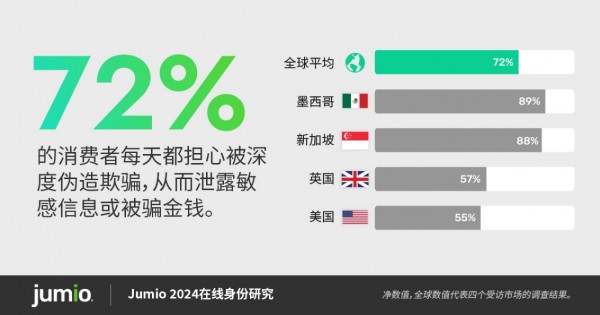
尽管人们对这种日益兴起且不断发展的技术感到高度焦虑,但消费者仍然高估了自己识别深度伪造的能力,60%的受访者相信他们可以检测到深度伪造,这一比例高于2023年的52%。在新加坡,这一数字高达77%。在全球范围内,男性受访者对自己识别深度伪造的能力更有信心(男性占66%,女性占55%),其中18-34岁的男性受访者表现出最强的信心(75%),而35-54岁的女性受访者最不自信(52%)。
Jumio首席技术官Stuart Wells表示:“随着生成式人工智能技术的进步,深度伪造的发生频率持续上升,这表明我们检测这些欺骗行为的整体能力还存在巨大差距。这种持续的过度自信更反映出加强公共教育和使用更有效的技术解决方案的必要性。企业和消费者必须合作强化数字安全措施,以有效防止身份欺诈。”
绝大多数(60%)的消费者呼吁政府加强对人工智能的监管以应对这些问题。然而,对政府监管的信任程度在全球各地各不相同,69%的新加坡人表示相信政府监管人工智能的能力,而英国仅为26%,美国为31%,墨西哥为44%。
网络欺诈的真实成本
欺诈是全球很多消费者都十分熟悉的问题,68%的受访者表示,他们遭受过或怀疑自己曾经遭受网络欺诈或身份盗窃,或者他们认识受到过欺诈的人。美国消费者最有可能直接成为欺诈的受害者(39%),无论是明知还是怀疑,而新加坡是报告认识受害者最多的国家(51%)。
在遭受或怀疑遭受网络欺诈或身份盗窃的消费者中,近一半(46%)的人表示这种经历只是带来了轻微的不便,但是32%的人表示这种经历造成了严重的问题,需要花费数小时的操作才能解决,14%的人甚至称之为一次痛苦的经历。
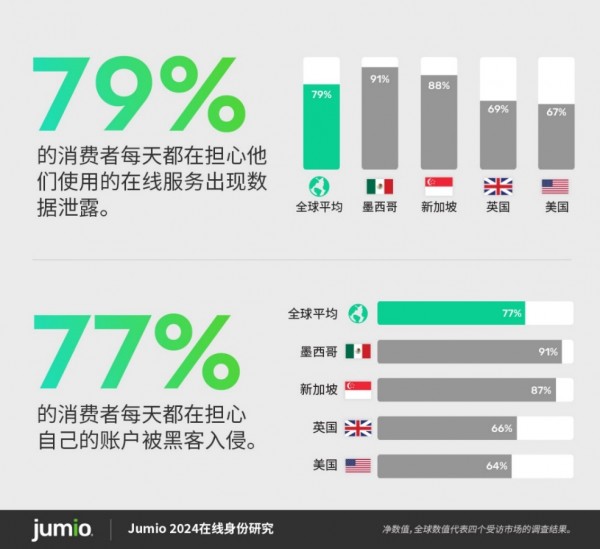
无论是否成为欺诈或身份盗窃的受害者,大多数消费者每天都担心成为数据泄露(79%)和账户接管攻击(77%)的受害者。
平衡身份验证的安全性和用户体验
对于希望保护自身安全并确保用户真实性的公司来说,身份验证是解决方案的关键部分。超过80%的新加坡消费者表示,如果这些措施能够提高金融服务(85%)、共享经济 (85%)、医疗健康(85%)、政府事务(84%)、旅游和酒店(84%)、零售和电子商务(83%)、社交媒体(82%)和电信(82%)等行业的安全性,他们愿意花更多时间进行身份验证。
在创建新的在线帐户时,全球消费者表示,拍摄身份证件照片和实时自拍照将是最准确的身份验证方式(21%),创建安全密码次之(19%)。
Jumio数字身份主管 Philipp Pointner表示: “在我们应对生成式人工智能带来的复杂性时,复杂的安全系统的作用变得至关重要。为了应对深度伪造和网络欺骗的兴起,采用基于生物特征的多模态验证系统势在必行。这些技术是确保企业能够保护其平台和客户免受新兴网络威胁的关键,并且比密码和其他传统的、过时的识别和身份验证方法要强大得多。”
点击查看更多数据和见解:https://www.jumio.com/2024-identity-study。
这项调查由Censuswide进行,参与调研的8,077名消费者平均分布在英国、美国、新加坡和墨西哥。实地调查于2024年3月25日至4月2日进行。Censuswide遵守并聘用了市场研究协会的成员,并遵循基于ESOMAR原则的MRS行为准则,同时他们也是英国民意调查委员会的成员。
来源:业界供稿
好文章,需要你的鼓励


苹果48GB M5 Pro MacBook Pro创历史新低,直降300美元
B&H近期对多款M5 Pro MacBook Pro机型推出300美元优惠。14英寸M5 Pro版本(48GB内存+1TB固态硬盘)现售价2299美元,较原价2599美元节省300美元,且该配置在亚马逊无法购买,折扣机会更为难得。此外,16英寸M5 Pro版本(64GB内存+1TB固态硬盘)同样享有300美元折扣。B&H在多款高配MacBook机型上的定价已低于亚马逊,是近期可找到的最优价格。

AI助手越权了?南加州大学等机构揭示大模型代理的“权限失控“问题
FORTIS是专门测量AI代理"越权行为"的基准测试,研究发现十款顶尖模型普遍选择远超任务需要的高权限技能,端到端成功率最高仅14.3%。

Insta360 GO 3S复古套装:怀旧美学与4K影像的融合
Insta360推出GO 3S复古套装,将现代4K运动相机与胶片时代美学结合。套装核心仍是仅重39克的GO 3S,新增复古取景器、胶片风格滤镜、NFC定制外壳及可延长录制时长至76分钟的电池组。复古取景器模仿老式腰平相机设计,鼓励用户放慢节奏、专注构图。相机内置11种色彩预设及负片、正片等滤镜,同时保留FlowState防抖、4K拍摄及10米防水能力,面向热衷复古影像风格的年轻创作者。

荷兰Nebius团队:给AI“起草员“瘦身,大模型推理速度最高提升5倍的秘密
荷兰Nebius团队提出SlimSpec,通过低秩分解压缩草稿模型LM-Head的内部表示而非裁剪词汇,在保留完整词汇表的同时将LM-Head计算时间压缩至原来的五分之一,端到端推理速度超越现有方法最高达9%。
2024
05/16
11:21
分享
点赞

CarPlay 新增两款音频应用,让你的旅途更精彩
Insta360 GO 3S复古套装:怀旧美学与4K影像的融合
谷歌免费存储空间调整:未绑定手机号仅享5GB
美国三大运营商携手卫星技术,向信号盲区宣战
Flytrex无人机携手达美乐,可一次性送达两个大号披萨
欧洲最大3D打印公寓楼提前数月竣工
彼亚乔携手迪士尼推出Grogu主题自主跟随货运机器人
Okta将AI智能体安全管理扩展至Amazon Bedrock并向第三方身份提供商开放
苹果13英寸iPad Pro Magic键盘键盘亚马逊历史低价,直降25%
WhatsApp iOS版Liquid Glass界面设计正式向更多用户推送
OpenAI为ChatGPT Pro推出个人财务管理新功能
赛格威全新Xaber 300电动越野摩托车正式开售,最高时速达96公里
最热门的 AI 模型:它们的功能和使用方法
这款古怪的 AI 智能手机可以创建你的数字分身
Faireez 获 750 万美元融资,为租赁市场提供 AI 驱动的酒店式管家服务
Broadcom 大获全胜:70% 大型 VMware 客户购买其最全面解决方案
Peer 获得1050万美元元宇宙引擎投资,推出3D个人星球功能
获 3000 万美元融资,Crogl 发布面向安全分析师的全新 AI "钢铁侠战衣"
Turing 获得 1.11 亿美元融资,估值达到 22 亿美元,为 OpenAI 等大语言模型公司提供关键代码支持
Tavus 推出系列 AI 模型,实现实时人脸交互技术突破
Welevel 获得 570 万美元融资,革新程序化游戏开发
AI 驱动的卓越运营:企业如何通过人人可及的流程智能提升成功
