
未来网络如何助力东数西算 原创
东数为什么要去西算?东数如何才能西算?当记者从工信部公布的数据中了解到,2021年全国数据中心耗电量,相当于1.3个上海市的社会用电总量时,就对将数据中心安置到电力充沛的西部有了充分的认同。但东数如何才能实现西算,这个问题直到第六届未来网络发展大会上,才获得了解答。
近期,第六届未来网络发展大会在江苏省南京市举办。大会以“网络全球决胜未来”为主题,围绕确定性网络、6G通信、算力网络、工业互联网、网络智能等话题,聚集了超1000位未来网络领域专家、行业代表共话未来网络发展。在会后的采访中,新华三集团副总裁、技术战略部总裁刘新民,新华三集团江苏代表处总经理谢莉,新华三集团2029研究院技术总监朱仕银,介绍了新华三如何与江苏省未来网络创新研究院合作,共同研发确定性网络,并由新华三承建了全球首张确定性网络试验网的具体情况。
承载算力的确定性网络
通常算力需要尽量的与数据靠近,这样才能获得更高的计算效率。比如在一台电脑中,与CPU距离最近的,必然会是内存,这样才可以在更短的时间内,将数据更高效的向CPU进行传输。可是在实施东数西算时,距离这个鸿沟又将如何跨越过去呢?
对此,刘新民的回答是“网络传输优化”。
新华三集团在近两年中,始终在与科研院所合作,研究如何攻克远程数据传输的链路损耗问题。通常100G的带宽,大概可以实现60G左右的流量传输。但在远程数据转输时,受到多条路由、时延、抖动的影响,60G流量的有效传输率只有30%。这也是为什么以前数据中心都尽力在东部进行建设的一个主要原因。因为那里的数据产生的最多,为了避免数据传输损耗,算力只能被迫向数据中心靠近。
如今通过网络传输优化技术,可以通过确定性网络使得100G带宽的传输效率提升2-3倍,达到90G的有效传输。如此一来,距离将不会再成为建立数据中心的主要制约因素。我们自然可以去环境更适宜、绿色能源更加丰富的西部地区去建立数据中心,从而令东数西算的目标得以实现。
确定性网络的实现原理
远距离传输损耗的难题,确定性网络又是如何加以克服的,对于这个问题朱仕银为我们更加深入的进行了讲解。
要想实现确定性网络的高性能数据传输,首先是要让数据不用“等”。数据在光纤中进行传输,速度基本上就是光速,传输距离实际上对数据传输的影响并不是很大,但是在远距离传输时会经过多个路由转发设备,在每次经过的时候,都要进行相应的网络协商,传输速率也就这样被降下来了。于是确定性网络的首要目标,就是让远距离传输的数据不用“等”。通过统一的管理控制机制,为数据事先建立好一条顺畅的通道,在经过每个路由设备时,都可以直接进行通过。
其次是利用新协议,现在主流传输协议是TCP,但TCP协议的拥塞控制并不理想,导致传输带宽利用率并不理想,从而会导致传输效率降低。在本次大会上,新华三集团就向外发布了利用RDMA方式替代TCP协议的确定性网络传输方案。RDMA协议要求零丢包、低延迟,以往只能在局域的数据中心内采用,如今有了不用“等”的确定性网络,也就可以让RDMA从局域网扩展到了广域网进行使用。网络带宽利用率,也提升到了现在的80-90%。

在会场外,新华三还搭建起了确定性网络的测试展示平台,利用思博伦测试仪表向发出确定性网络和背景数据传输流量,并通过以上图中所示的两个加载多跳路由的路由器进行数据转发,为了模拟远距离数据传输,还通过链路损耗测试仪表,为其添加上了相当于1000公里的延迟。
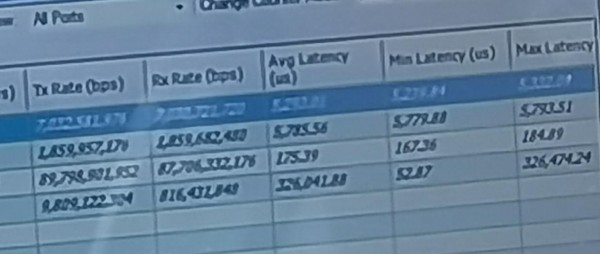
在实时测试结果中我们可以看到,其最小和平均延时只达到一百多微秒,双向传输速率也分别达到89和87Gbps。
通过新华三集团各位技术专家深入浅出的讲解,以及现场的实际测试展示,我们切实体验到了确定性网络在远距离数据传输时的神奇之处,也更加有理由相信,通过确定性网络对算力的承载,东数西算的宏伟目标必然会更加顺利的得到实现。
好文章,需要你的鼓励


大众汽车推进平价电动车战略,两款新车率先下线
大众汽车旗下ID. Polo与Cupra Raval已在西班牙马托雷尔工厂正式下线投产。两款车型起售价分别为24,995欧元和26,000欧元,均基于MEB+平台打造,搭载37kWh或52kWh电池组,续航里程最高可达454公里。这是大众"电动城市车家族"系列的首批产品,预计今年夏末秋初开始交付。大众集团通过跨品牌资源整合,实现约6亿欧元的成本节约,后续还将推出ID. Cross等新成员。

当AI机器人“自信地“撞向墙壁:STATE16研究院揭示物理AI系统中那些无声无息的致命错误
STATE16研究院这篇综述发现,物理AI系统存在"静默失效"风险——AI以高度自信执行基于错误世界信息的动作,却不触发任何报警,并提出在AI输出与物理执行之间建立独立授权层的框架。

三星Health应用迎来AI升级,Galaxy Watch 9发布前夕更新提前揭晓
三星宣布将于6月8日起为Samsung Health应用推出重磅功能更新,赶在Galaxy Watch 9传闻发布之前落地。新版本将引入多项AI驱动的生物特征分析功能,包括:综合心率、血氧、皮肤温度等数据的每日活力评分(Vitals)、结合体成分数据评估长期心脏健康的心脏健康评分、优化训练强度的每日有氧负荷追踪,以及横向对比用户群体的健身指数。此外,应用界面将重新划分为睡眠、营养、活动、正念和体征五大板块,并新增抗氧化指数、年龄指数和听力保护等个性化功能。

当AI学会“边干边学“:UIUC与微软联合打造的网页智能体训练新范式
UIUC与微软联合研发的OpenWebRL框架让4B小模型仅凭400条初始数据,通过在真实网站上边做边学的强化学习方式,在网页智能体基准上超越了用27万条数据训练的竞争对手。
2022
09/13
11:18
分享
点赞

三星Health应用迎来AI升级,Galaxy Watch 9发布前夕更新提前揭晓
Meta智能眼镜被曝含"人脸识别"追踪代码,隐私风险引发警示
Gemini企业智能体平台的智能体RAG如何实现可靠响应
麻省理工学院AI与计算研讨会:技术进步中不可或缺的人文因素
亚马逊全新数据中心路由架构降低AWS网络能耗40%
iOS 27即将发布,多款iPhone应用将迎来全新设计升级
连接性已成为与计算和存储同等重要的AI基础设施核心要素
开发者仍在等待Meta最新AI模型的API访问权限
迈向Token经济时代,F5以“AI赋能交付”筑基智能新生态
米拉·穆拉提重返公众视野,谨慎发声
特斯拉疑似删除FSD证据,卡特彼勒加速电动化布局,高压系统技术培训刻不容缓
智能体网络流量首超真人访问,"死亡互联网"理论引发新争议
