
迎接Edge 2.0,创新数字经济
本文源自F5公司CTO林耕于近日在清华大学的一场圆桌会议上的发言,阐述其对于数字经济发展和Edge 2.0时代的看法。
2020年开始席卷全球的 “新冠” 疫情给全世界带来了更大的变数,但危与机的博弈中,世界的变化并非毫无章法。我们发现,疫情加速了全球数字化的进程,微软CEO Satya Nadella就曾经说过: “在过去几个月内,我们见证了多年才能实现的数字转型进展。”
今天,全球都在走向数字化。根据全球移动通信系统协会(GSMA)统计数据显示,2025年全球联网设备的数量将达到约246亿个。据IDC和Gartner,全球数据量大约每两年就将翻一倍,到2025年,这个数字将疯狂攀升至175ZB,届时大约有超过75%的数据将在边缘侧处理。
可见,万物互联的时代真的来了,它催生了边缘计算的崛起和迭代,并将在未来快马加鞭融入企业乃至社会生活的方方面面。
互联网的第三次浪潮——万物互联的Edge2.0时代
在我看来,边缘计算的崛起和演变将成为互联网第三次浪潮的标志性事件。众所周知,信息技术的变革推动人类走过了PC与互联网时代,以及移动互联网时代,如今向着移动物联网时代迈进。这种进化突出地表现为网络生态系统结构的变化,从静态且封闭的Edge1.0,走向开放和自动化的Edge 2.0,整个过程犹如从单细胞生物到复杂生命体的进化之旅。
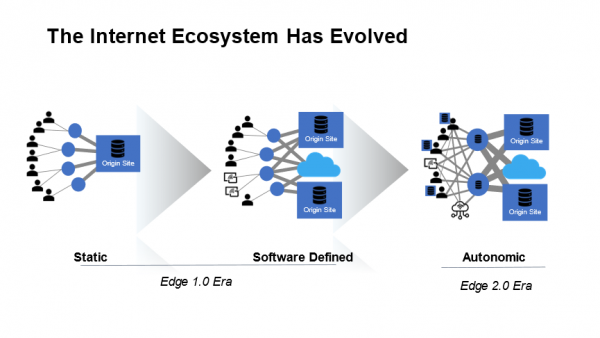
更为重要的是,边缘计算正在成为促进行业数字化转型的重要抓手。根据F5刚刚发布的《2021年应用策略现状》报告,76%的企业已经实施或正在积极规划边缘部署,而增强应用性能和收集数据/执行分析是主要推动力量。
新一轮的数字化转型中融入了海量的“物” 元素。过往,由于IT(信息技术)与OT(运营技术)彼此分离,尽管云计算带来了算力的极大提升,但物的加入仍然给云模式下的网络架构带来挑战。而在 Edge2.0时代的移动物联网环境中,IT与OT将真正融合起来,并具备更强大的智能感知和自动化能力。换言之,在由云计算的集中式数据处理模式之外,网络边缘将汇集海量设备与数据,并提供靠近终端的强大算力,由此激发巨大的商业价值。
另一方面,边缘网络上的设备与数据增速将远超过核心基础架构能力的增长速度,由此在端到端的应用交付链条中容易形成阻塞点,且边缘计算对于时效性更敏感,延迟将给系统稳定和应用体验带来近乎致命的打击,安全性的挑战也将显著增加。
创新应用交付,从容驾驭互联网新浪潮
对于多数企业而言,实现云端、边缘到终端的一体化应用部署,形成一套有别于当前核心架构的应用交付模式,将是一条通往Edge2.0时代的有效路径。当前,应用和服务交付基本围绕集中模式而构建,并在公有云或私有数据中心内托管。而在Edge 2.0时代,基础架构、数据架构和应用架构都将向更加分散的点对点方向发展。
基于对多云应用安全和应用交付服务技术的多年深耕,F5 始终服务于数字时代中的“应用”这一组织的核心资产。边缘2.0时代的网络由封闭转向开放,F5所提供的解决方案,通过统一的代码,让每个应用安全或交付服务运行在任何服务器和任何云环境中,并实现从云、边缘到应用的覆盖端到端的安全防护,为客户带来 “感知可控,随需而变” 的应用体验。
如今,各行各业都在数字化转型的大路上加速奔跑。我们相信,边缘部署将逐渐成为客户应用策略的一部分,我们也期待与客户携手,在这场互联网的新浪潮中继续“乘风破浪”。
Source:
- 安防知识网:2025年全球物联网总连接数规模将达到246亿https://www.asmag.com.cn/news/202004/103199.html
- 物联传媒-维科网:对比云计算的发展,边缘计算的机会正在孕育https://iot.ofweek.com/2021-01/ART-132214-8500-30482104.html
- https://www.microsoft.com/en-us/microsoft-365/blog/2020/04/30/2-years-digital-transformation-2-months/
好文章,需要你的鼓励


微软全新AI图像工具在关键评测中超越谷歌Nano Banana
微软在Build开发者大会上发布了两款新文生图模型——MAI-Image-2.5与Flash版本,同时还推出了首个推理模型MAI-Thinking-1及多款语音、转录和代码模型,共七款新AI模型。根据Arena AI排行榜评测,MAI-Image-2.5在图像编辑能力上已超越谷歌Nano Banana 2,但仍位居OpenAI GPT-Image-2之后。新图像模型现已集成至PowerPoint、Foundry企业市场及OneDrive,主打精准编辑与专业级输出能力。

港科大广州等机构提出DRIFT:让AI在对话中边犯错边学习,效率媲美普通训练
DRIFT方法通过数学等价关系,将多轮对话强化学习目标转化为带权重的监督学习,效率接近普通SFT,性能媲美在线强化学习。

Alphabet创850亿美元融资纪录,AI投资热度持续高涨
Alphabet母公司谷歌完成了一笔创历史纪录的850亿美元股票发行。原计划首轮募资400亿美元,但因超额认购最终达450亿美元,伯克希尔·哈撒韦认购了其中100亿美元。所募资金将专项用于AI基础设施建设。此次融资成功对Anthropic等AI公司的IPO计划是积极信号,表明公共市场投资者对AI赛道仍保持强劲热情。未来五年全球AI支出承诺规模近8万亿美元,公共资本市场能否持续承接这一体量,是所有谋求上市的AI企业必须思考的核心问题。

Megagon Labs教AI学会像工程师一样“反思“:一套让大模型自动打磨提示词的新方法
RPT是Megagon Labs提出的提示词自动优化框架,通过诊断失败模式、维护历史记忆、纳入置信度校准,让AI像工程师一样系统地改进自己的"说明书"。
2021
05/07
10:12
分享
点赞

微软全新AI图像工具在关键评测中超越谷歌Nano Banana
Alphabet创850亿美元融资纪录,AI投资热度持续高涨
欧盟推进技术主权计划,降低对美国科技公司的依赖
智能体如何突破三大障碍,重塑客户服务格局
我用真实病历测试了微软Copilot Health,结果出乎意料
AI引发认知疲劳,如何在高效工作中保持清醒?
基准测试是一个过程,而非一个数据集
Tod Machover荣获乔治·皮博迪奖章,彰显其在音乐与科技领域的卓越贡献
思科:量子网络将成为下一代网络的未来
Gemini Go正式上线,取代Android Go手机上的谷歌助手
Amazon Music将对部分Prime会员展示广告并取消下载功能
Google Photos安卓版新增贴纸收藏夹功能
