
金融科技数据链的DNA
2020金融街论坛年会上, 央行副行长范一飞谈到金融与科技融合发展的新举措, 第一条就是“固本强基,发挥数据要素倍增作用”, 强调深挖应用场景, 运用海量多维数据实现“信息整合,特征关联和业务洞察”。正式将金融企业打通“云-管-边-端”的金融科技数据链, 实现信息整合, 特征关联提上了金融科技的议事日程, 以BATJ带来的互联网体验作为参考标准, 在国产化大环境下实现服务可达, 通过VIP用户访问的全栈溯源, 确保提升用户体验。
 博睿数据COO 吴静涛
博睿数据COO 吴静涛
95后逐渐成为了消费市场的主力,从小生活条件优越的Z世代,有着巨大的消费潜力,他们更加渴望自由而弹性的生活,特别是对在线服务的可用性和体验的要求极高。在金融企业的数字化转型过程中, 将会面临传统的数据中心管理转型的新挑战, 比如:用户体验监控, CDN边缘节点监控, 云原生服务监控, 微服务监控等, 而融合这些新的监控管理手段, 打通金融科技数据链, 将会成为新一轮的科技创新热点, 用来提升服务的可用性, 提升用户体验, 应对Z世代的高要求。
以电子银行为例, 金融科技数据链的打通需要到DNA的三个环节, 分别是:
- DEM (Digital Experience Management): 用户数字体验管理,
包含客户端APP体验监控, 浏览器体验监控, 小程序体验监控, 浏览器拨测和手机真机拨测等一系列技术。
- NPM (Network Performance Management): 网络性能管理,
通过探针技术、 BigIP大数据引擎、Nginx Telemetry等技术, 实现网络传输的路径发现, 异常发现, 故障发现。
- APM (Application Performance Management): 应用性能管理,通过字节码注入和微服务探针, 无需应用代码变更的情况下实现对代码运行效率, SQL调用效率, PaaS API调用逻辑追踪, 以及微服务的性能监控。
取得了不同环节的体验数据, 网络数据和代码执行效率数据后, 需要通过DataView的大数据平台实现信息整合, 和特征关联. 实现对VIP用户访问的访问过程全栈溯源, 提升用户体验; 同时实现机器学习后的智能基线, 智能警报; 再通过AI人工智能实现根因分析, 提出解决建议和方法, 甚至通过API调用验证过的预配置, 实现一键变更和一键割接。
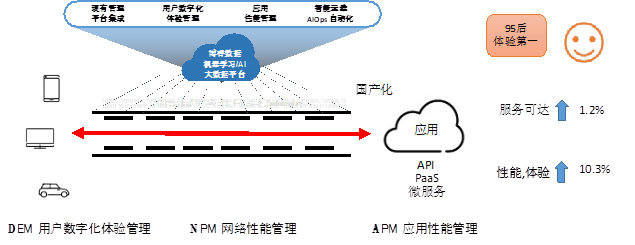
根据目前客户的使用状况, 金融科技数据链DNA的架构可以帮助客户发挥数据要素倍增作用:
1. “信息整合”: 将用户体验数据, 网络性能数据, 应用性能数据, 应用可用性数据等信息整合, 实现统一收集, 统一存储, 统一管理, 通过API调用的方式实现一次采集, 各部门的多次订阅消费, 某客户反馈关于服务可达能力提升时说: 1.2%的服务可达提升, 可不仅仅是体验提升而已, 光数据中心1.2%的耗电节省, 就是博睿数据带给我们很大的价值了。
2. “特征关联”: 通过大数据分析和用户标识, 建立用户访问, 网络传输, 云服务, API调用等各环节的关联关系, 实现全栈溯源, 真正帮助电子银行业务, 在保证稳定可靠的社会责任的同时, 融合现有平台、云原生平台、国产化平台、微服务平台的监控管理手段, 某大行用户的电子银行发现, 用户登陆失败的部分原因是运营商的认证短信延迟导致, 通过博睿数据定制对客户与运营商间的短信网关监控, 发现和排除关联故障, 建立服务品质的数据标准, 提升本行与运营商的议价能力并提升用户体验。
3. “业务洞察“: 用财务语言汇报数据中心的投入产出, 建立带宽、算力、存储等基础设施投资后, 发现具体的用户体验/用户留存率/月活提升、 API调用效率提升、以及代码运行效率提升之间的相互关联关系, 为业务拓展提供直接参考。
金融科技数据链DNA, 通过大数据平台打通“云-管-边-端”, 并通过机器学习和人工智能实现“信息整合,特征关联和业务洞察”, 帮助金融企业在国产化大环境下应对Z世代对服务可达, 应用体验的高要求,在稳定可靠和灵捷快速之间取得相对平衡, 促进金融与科技融合发展。
好文章,需要你的鼓励


苹果在印度恢复银行卡支付功能,距暂停已逾四年
苹果已开始在印度分阶段恢复Apple账户的信用卡支付功能,用户可绑定Visa和Mastercard信用卡及借记卡,用于购买iCloud+、Apple Music订阅及App Store应用。此前,由于印度储备银行于2021年推出新的周期性支付监管框架,苹果于2022年5月暂停了该支付方式。此次恢复标志着苹果在适应各国本地化监管要求方面的持续努力,同时也引发外界对苹果是否将在印度推出Apple Pay的新猜测。

当AI遇上小语种数学题,慕尼黑工业大学等多机构联手揭示大模型的“偏心“有多严重
这项来自慕尼黑工业大学等多机构的研究(arXiv:2607.05992)推出PLURAMATH基准,将多语言数学推理评测扩展至18种低资源语言,用27个AI模型揭示了语言资源丰富程度与模型数学推理性能的强相关,证明换语言提问无法弥补这一差距。

Bookshop.org确认今年将推出Kobo电子书阅读器支持
Bookshop.org创始人Andy Hunter证实,与Kobo的合作集成将于今年落地。此前该计划历经多次推迟,网页措辞一度从"2026年"改为"未来某时"。Hunter表示,双方已就商业条款达成一致,工程团队正将资源重新投入Kobo支持开发,但尚无具体上线日期。该集成将支持数字版权管理要求,让用户通过Bookshop.org购买电子书,同时支持独立书店。

复旦大学与腾讯混元联手,让AI“学徒“训练效率提升2.29倍的秘密武器
复旦大学与腾讯混元联合提出TurnOPD,通过自适应截断和渐进式损失再分配,将长程AI智能体的在线蒸馏训练效率提升最高2.29倍。
2021
04/14
19:48
分享
点赞

可口可乐旗下Fairlife乳品公司遭勒索软件攻击,被迫停产
从上海到世界:WAICA正以“AI原生”范式重写顶会规则
从主机节点到异构机架:重新思考AI CPU
苹果在印度恢复银行卡支付功能,距暂停已逾四年
Bookshop.org确认今年将推出Kobo电子书阅读器支持
WeWard新增"步行模式":走够步数才能解锁应用
X将通过私信通知用户其互动帖子被社区笔记纠错
"慢社交"应用Roost:让消息像真鸟一样飞行
Truecaller与印度电信监管机构就反垃圾电话规则展开公开交锋
Block与46州达成4500万美元和解,涉Cash App欺诈纠纷
欧盟威胁对Meta开出罚款,剑指Facebook和Instagram上瘾性设计
Disney+考虑推出免费流媒体内容层级
