
Aruba发布业界首款服务智能边缘的云原生平台Aruba ESP
至顶网网络与安全频道 06月22日 综合消息:慧与公司旗下的Aruba近日推出业内首款 AI 驱动的云原生平台 Aruba ESP(边缘服务平台),该平台建立在 AIOps、零信任网络安全和统一架构基础上,提供跨网域数据的持续性分析、跟踪 SLA,识别异常情况并进行自动优化的平台,同时监控网络上的未知设备以确保设备安全。Aruba ESP旨在为网络边缘提供云体验,可作为云服务或本地服务使用,也可由Aruba合作伙伴提供托管服务,抑或通过HPE GreenLake获取相应服务。此外,Aruba还提供了 HPE 金融服务,客户根据自身预算和运营要求灵活购买该服务平台。
科技领域近20 年的重点是提供无处不在的移动性,之后逐渐转向基于云的应用程序。如今则步入了由计算和现代网络支持的,由物联网、人工智能和自动化驱动的数据化时代。因此,企业在网络边缘会生成大量的非结构化数据,要将这些实时数据分析转化为有意义的行动,关键是要在人、设备和万物连接到网络的起点——也就是我们所说的“边缘”——对这些数据进行分析和处理。
Aruba ESP三大“硬核”,驾驭未来智能边缘
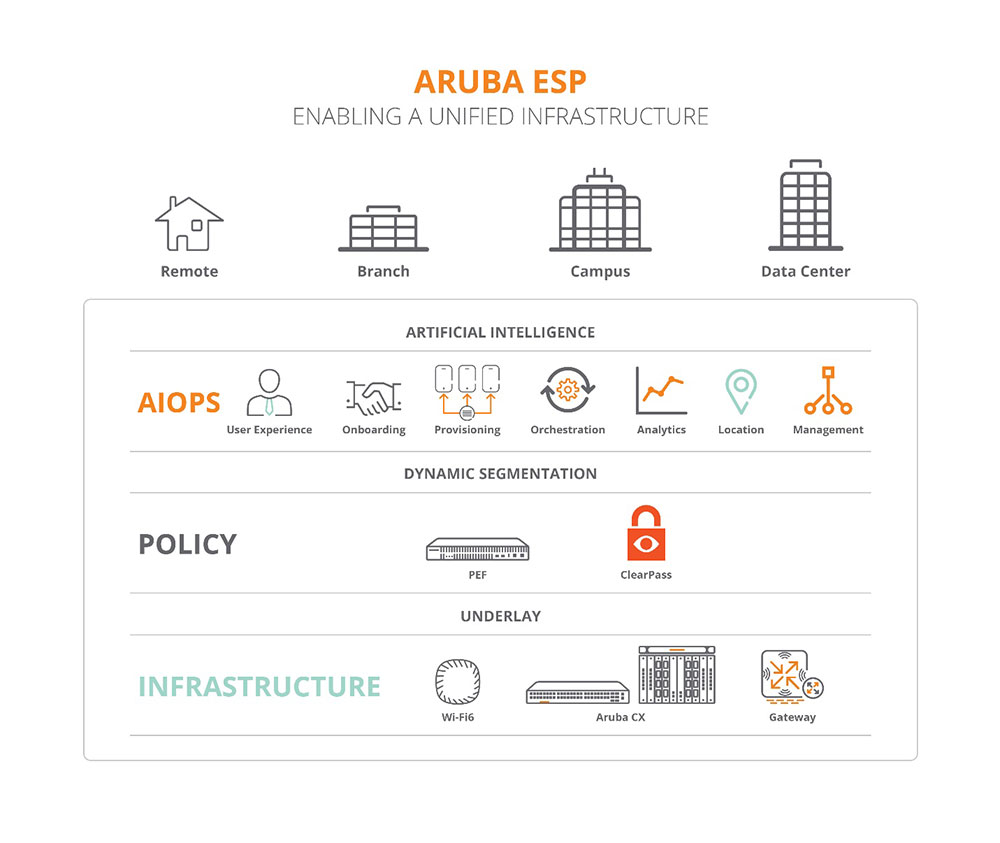
利用边缘的非结构化数据需要通过网络遥测技术、利用人工智能,以远超人类能力范围的速率和体量对这些数据进行处理。这需要一种由AI驱动的具有“第六感”的基础设施,以提前识别潜在问题,精准制定解决方案,并实施自动化的操作,整个过程无需人工干预。Aruba ESP提供了一个本地或云端的单一云原生平台,基于以下核心原则对企业网络给予全面的保护并对基础设施进行统一管理:
- AIOps是 Aruba ESP 的关键构成,人工智能技术和丰富的分析工具对网络问题根源的判断准确率高达95%,并可自动修复这些问题,主动监控用户体验,在问题发生之前对网络进行调整与优化。在实时的部署中,AIOps可使网络吞吐量增加25%,问题解决时间缩减近90%,极大地改善了用户体验。
- 统一的基础架构整合了 Aruba Central云网络综合管理平台(一个云原生统一的控制台,可对跨网域事件进行关联,以减少问题解决时间和人为错误)下所有园区、数据中心、分支机构和远程工作环境中的交换机、Wi-Fi 和 SD-WAN 的网络操作。此外,Aruba的统一基础架构允许客户在本地部署和公有云服务之间进行选择,给予他们以最大的灵活性。
- 零信任网络安全功能将内置的基于角色的访问技术、动态网络隔离和基于身份的入侵检测相结合,以验证、授权和控制每一个连接到网络的用户和设备,可在网络漏洞影响业务之前对其进行检测、预防、隔离和阻止。
发布会上,Aruba 总裁及联合创始人 Keerti Melkote表示:“智能边缘是一种催化剂,为那些将技术投资作为最要资产,并且希望以此加速转型和确保业务连续性的组织与企业创造了无限可能。可以说,Aruba ESP是Aruba多年技术创新的结晶。同时,来自客户的中肯反馈和建议帮助我们将它打造成为一个更加完美的智能的网络方案。”
Aruba ESP 背后的创新“黑科技”
Aruba ESP 是目前业界可扩展性最高的全栈云原生平台,适用于有线网络、无线网络和 SD-WAN 环境,整合多种网络元素以实现集中管理和控制。Aruba ESP 基于Aruba 的基础架构进行了优化,采用开放标准,可与第三方的解决方案与服务进行集成。这些重大创新还包括:
- 适用于任何企业规模的云原生管理平台 — Aruba Central云网络综合管理平台目前为超过65,000名客户运行关键业务网络。现引入全新的 ArubaOS 服务,使 Aruba ESP 成为业界唯一基于云的,能够为不同规模的园区、数据中心、分支机构和远程工作位置的网络提供全栈管理和操作的平台。
- 通过统一的基础设施简化日常操作 — 最新版本的 Aruba Central可通过 Aruba ESP 访问公共数据池,使用简化的导航、高级搜索和上下文视图对功能进行强化,通过单个控制点呈现多维度的信息,无需使用繁杂的工具即可收集和关联跨网域和位置的信息。
- 人工智能和自动化缩短问题解决时间 — Aruba 在独有技术方案 Aruba ClientMatch等AI驱动的创新已积累了十多年的经验。根据 100多万个网络设备每天15 亿个数据点生成的建模数据,新推出的 AI Insights 可识别那些难以发现的网络配置问题并提供原因分析、指导建议和自动修复,从而缩短故障排除时间。
- AI驱动IT效率提升 — Aruba Central的AI辅助功能使IT团队仅用简单的英语语言查询功能,便可从Aruba ESP通用数据池所呈现的上下文中信息中提取全面的用户和设备数据,以迅速解决问题。对于更复杂的问题,AI辅助功能通过事件驱动的自动化技术去收集和发布所有相关数据,为内部帮助台及Aruba技术援助中心(TAC)提供支持。
- 跨应用程序、设备和网络的细粒度可见性 — Aruba Central的增强功能支持User Experience Insight 进行以用户为中心的分析,以更快地确定客户端、应用程序和网络性能问题。
- 将下一代交换技术扩展到分布式和中型企业 — 为了帮助企业加快边缘转型,Aruba 扩充了CX 交换机系列的产品阵营,发布了新的 Aruba CX 6200 交换机系列。该系列产品可将内置的分析和自动化功能应用于任意网络边缘。同时,CX 6200 系列交换机支持从企业园区和分支机构接入层到数据中心的单一操作模式。
- 开发者中心推动持续创新 —Aruba 推出了面向开发人员的综合资源服务 Developer Hub,包括 Aruba API 和文档,利用开放的 Aruba ESP 平台简化下一代创新型边缘应用程序的开发。

詹姆斯·库克大学的高级基础架构工程师 Ron Gardner 说:“我们的大规模网络跨多个校区和学习中心,这些区域运行着性能要求十分严格的应用程序,以保证师生和研究人员的互通互联与高效工作。Aruba Central 和 ArubaOS 的增强功能可在简化网络运维的同时减少设备占地面积,并从云端管理大型校园网络和分布式位置,最终,我们能够在问题干扰网络正常运行之前主动发现并解决它们。”
休斯顿大学信息技术网络管理员 Brandon Stratton 表示:“鉴于基础设施的规模和边缘产生的海量数据,我们需要一种可以对网络进行自动识别、修复和微调的方案。Aruba 基于人工智能的专业解决方案,比如 NetInsight,带来更实用的方法,帮助我们进行分析并根据此采取行动。”
据悉,为了满足组织快速变化的业务和技术需求,Aruba 增加了采购的可选方案,包括通过 Aruba 的 HPE GreenLake获得服务,通过 HPE 金融服务购买具有灵活采购方案的 Aruba ESP等举措。例如,客户只需在合同生效后的8 个月内每月支付合同总价值的 1%,即可获得相应的技术方案,剩余的 超过90% 的费用可推迟到 2021 年支付。
好文章,需要你的鼓励


Rocket Lab宣布以80亿美元收购卫星运营商铱星公司
火箭实验室(Rocket Lab)宣布计划以现金加股票方式,斥资80亿美元收购主要卫星运营商铱星通信(Iridium Communications),交易预计于2027年中完成。铱星目前运营着由66颗活跃低轨卫星组成的星座网络,拥有约255万活跃用户,2024年营收达8.717亿美元。收购完成后,Rocket Lab计划借助其新型重型运载火箭Neutron及Lightning卫星平台,扩大铱星星座规模,开拓未被覆盖的市场并降低发射成本。

腾讯混元视觉团队打造“图像翻译官“:让AI用离散数字读懂每一张照片
腾讯等机构提出ViQ框架,通过两阶段渐进量化训练,让离散视觉编码在多模态理解和图像重建上同时追平连续特征编码器,训练速度最高提升70%。

Tidal宣布将为AI生成音乐添加标签并移除欺诈内容
音乐流媒体平台Tidal宣布,将于7月中旬启用自动化工具,对完全由AI生成的音乐添加"AI"标识,并移除具有欺诈性质的曲目。平台还将取消AI生成音乐的版税资格,仅向真人创作、演唱的原创音乐开放变现渠道。此外,Tidal明确将高频异常上传、干扰真实艺术家等行为列为欺诈活动。Deezer、Spotify等竞争对手此前已推出类似检测机制,流媒体行业正加速构建AI内容治理体系。

香港科技大学联手华为研究院:AI绘图训练速度提升2.78倍,秘诀藏在“概率分工“里
香港科技大学与华为联合提出LISA训练方法,通过让副网络对齐"似然分数",将ControlNet等图像生成模型的训练收敛速度提升逾2.78倍,同时改善图像质量与条件控制精度。
2020
06/22
16:43
分享
点赞

Rocket Lab宣布以80亿美元收购卫星运营商铱星公司
Tidal宣布将为AI生成音乐添加标签并移除欺诈内容
Claude Tag:将职场AI从个人助手升级为团队协作伙伴
数百万颗超新星爆炸或将揭开暗能量的秘密
Base44发布自研大语言模型,氛围编程平台寻求核心竞争壁垒
遗留系统与数据鸿沟制约亚洲财资中心发展
机器人手部公司与特斯拉达成商业秘密诉讼和解,完成1100万美元融资
OpenAI携手Trail of Bits发起"Patch the Planet"开源安全修复计划
想进大厂?初创公司或许才是你的最佳跳板
公共电力性价比优势面临多年来最严峻考验
特斯拉开始向HW3车型推送FSD v14"精简版"
新品牌Gobao推出电动自行车快充电池与eCVT驱动系统
