
国家信息中心联合华为发布 《迈向万物智联新世界--5G时代·大数据·智能化》研究报告
今天,2019中国国际智能产业博览会在渝盛大开幕,期间国家信息中心联合华为及其他学术机构撰写的研究报告《迈向万物智联新世界--5G时代·大数据·智能化》在“智能化应用与高品质生活高峰论坛”上正式发布。该研究报告以高质量发展命题为主线,系统性阐述了5G时代大数据、智能化对未来社会各个产业及政府治理模式的全局变革和深刻影响,为中国未来信息化布局提出全面规划和建议。
国家信息中心副主任周民、国家信息中心大数据发展部主任于施洋、华为企业BG副总裁喻东、华为中国区数字政府业务部总裁刘正宝作为代表共同为研究报告揭牌。

喻东在开场致辞中指出: “以5G、大数据、人工智能为代表的新一代信息通信技术 (ICT),将为未来一段时期我国经济换挡提速提供强大动力,成为中国高质量发展的重要抓手。华为公司在5G、大数据、人工智能等领域一直在持续发力,并已经在智慧城市、园区、交通等行业领域积累了很多的经验。在5G时代我们将继续与政府、企业及伙伴紧密携手,锐意进取,共同为各行各业的发展,建设数字中国贡献力量。”

于施洋在报告内容分享的主题演讲中提到:“随着通信技术、互联网、人工智能、物联网等新技术发展,原有的产业链和价值链正在裂变重塑,新的生态系统正在加速涌现,万物互联化、数据泛在化的大趋势日益明显。作为下一代通信网络标准,5G的商用普及,将进一步推动这一趋势发展,迎接人类社会进入万物互联的智能时代。”

《迈向万物智联新世界》研究报告主要涵盖如下内容:
- 发展机遇:从入场、跟随到领跑
中国在移动通信标准和核心技术领域走过了从入场、跟随到领跑的发展历程。4G改变生活,5G改变社会。5G将会带来更宽广的联接场景和应用领域。5G的高宽带、低时延、大连接等特点,在与大数据、人工智能的融合下,会大大加速产业创新与发展,从而推动人类社会真正迈向万物智联的新时代。
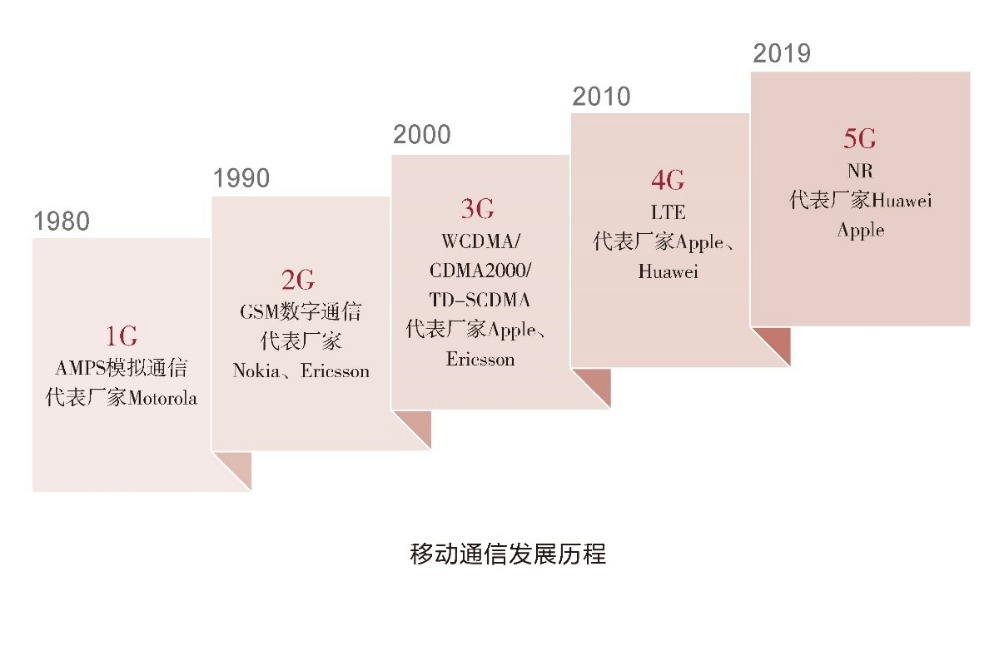
- 技术趋势:人工智能应用场景和边界将被极大拓宽
5G将带来人类历史上史无前例的数据爆炸式增长。预计2025年,非结构化数据量在总数据量中的占比将达95%,全球企业对AI的采用率将达86%。 借助大数据、人工智能手段进行更高效数据分析、处理、决策,将成为政府和企业核心任务之一。
5G、大数据及人工智能的深度交融,将极大拓宽人工智能应用场景和边界,使人工智能具备自主行动能力,形成可自闭环的智能体。随着智能芯片、智能算法、智能开发平台等不断迭代发展,在移动互联网、大数据、云计算、物联网等新ICT技术共同驱动下,人工智能呈现出深度学习、跨界融合、人机协同、群智开放、自主操控等新特征。
- 未来展望:5G、大数据、人工智能等数字技术是产业升级和创新的重要使能器
5G、大数据、人工智能等数字技术是产业升级和创新的重要使能器,将开启信息化发展的新征程,催生各行各业的不断创新。移动网络将使能全行业数字化,成为基础的生产力。5G的极致联接能力将促进政府和企业的数字化转型,改变人们现有的生产和生活方式,提升人们的生活品质和体验。
中国要迈入智能时代,需要依赖产业及行业的数字化与智能化。产业数字化转型已进入深水区,传统产业的变革与创新将提上日程。其中,5G、大数据和AI等数字化技术的深度融合将重构基础设施的智能大脑,产生大量智能化应用,从而推动全行业的数字化升级。

好文章,需要你的鼓励


仿人机器人视觉与运动技术的精细调校
仿人机器人与自动驾驶汽车在区域架构、功能安全及雷达传感方面高度相似。多分辨率摄像头组合可更好地模拟人类视野,兼顾广角低保真与局部高精度需求。自然运动需实时计算正逆运动学、距离与深度,同时须兼顾功耗效率。当前视觉与基础操控技术最为成熟,而触觉、全身协调及非结构化环境中的移动能力仍是主要挑战。业界正借鉴自动驾驶经验,加速推进仿人机器人的规模化落地。

当AI做“陪练老师“:弗吉尼亚理工大学等机构用大模型的“解题日记“预测考题难度
这项研究提出Epi2Diff方法,通过将大型推理模型的解题思考过程拆解为认知片段序列,提取过程特征预测考题对人类的难度,在四个真实考试数据集上超越了所有对比基线。

抵御AI驱动的数据融合攻击:芯片安全防护的关键挑战
随着AI技术发展,攻击者可融合白市、灰市及黑市数据,构建个人及其环境的数字孪生体,使定向攻击更为便捷。专家指出,AI与网络安全的核心交汇点是数据本身。防御AI数据融合攻击需依赖硬件信任根、强加密、安全密钥存储及严格的数据匿名化措施。芯片架构师需将安全设计嵌入硬件层,确保数据完整性验证、隔离执行及认证数据流,以应对日益复杂的运行时攻击面。

南京大学联手阿里巴巴:让AI图像生成变得更“聪明“,一个让图像生成模型真正理解画面的新框架
南京大学与阿里巴巴提出MIMFlow,将掩码图像建模与标准化流端到端融合,让生成模型专注语义建模,以更少参数和更少令牌在ImageNet上取得FID 2.50的优异表现。
2019
08/27
17:54
分享
点赞

仿人机器人视觉与运动技术的精细调校
抵御AI驱动的数据融合攻击:芯片安全防护的关键挑战
AI数据中心与汽车行业在能源管理领域的技术融合
GLM-5.2海外爆火,我们翻了1500条评论,看看用户在讨论什么
电动自行车的功过之辩:被忽视的那一面
Neo:印度科技大亨自掏3000万美元,打造微软Office的AI替代品
AI数据中心如何获得电网接入资格?公用事业公司的规划逻辑解析
Brookfield与Bloom能源将融资规模扩至250亿美元,押注AI数据中心独立供电
当CIO的技术提案遭到否决,该如何应对?
这款谷歌实验室 AI 应用如何成为我每日必用的工具
起亚EV5推出Storm特别版并新增全轮驱动选项
Meta效仿SpaceX,将过剩AI算力变现
最热门的 AI 模型:它们的功能和使用方法
这款古怪的 AI 智能手机可以创建你的数字分身
Faireez 获 750 万美元融资,为租赁市场提供 AI 驱动的酒店式管家服务
Broadcom 大获全胜:70% 大型 VMware 客户购买其最全面解决方案
Peer 获得1050万美元元宇宙引擎投资,推出3D个人星球功能
获 3000 万美元融资,Crogl 发布面向安全分析师的全新 AI "钢铁侠战衣"
Turing 获得 1.11 亿美元融资,估值达到 22 亿美元,为 OpenAI 等大语言模型公司提供关键代码支持
Tavus 推出系列 AI 模型,实现实时人脸交互技术突破
Welevel 获得 570 万美元融资,革新程序化游戏开发
AI 驱动的卓越运营:企业如何通过人人可及的流程智能提升成功
