
新华三发布《中国城市数字经济指数白皮书(2019)》——用数据记录城市数字化转型进程
2019年4月19日,重庆讯,在今日举行的2019 Navigate领航者峰会上,紫光旗下新华三集团(以下简称“新华三”)数字经济研究院正式发布《中国城市数字经济指数白皮书(2019)》(以下简称“2019版白皮书”),为城市数字经济发展提供精准画像,客观评价国内城市的数字经济发展水平。

新华三集团副总裁、解决方案部总裁李立在峰会现场发布2019版白皮书
持续扩大视角,打造更为系统的研究评价体系
2017年新华三发布的《中国城市数字经济指数白皮书(2017)》是业内首个面向国内城市数字经济领域的评价白皮书,发布了对中国40余个城市的数字经济发展评价结果。2018版白皮书则将研究范围扩大到100个城市。经过持续的沉淀积累,2019年,新华三重磅推出涵盖8个城市群+113个城市+50个县市的白皮书,构建“城市群-城市-县市”三位一体的立体研究体系。
2019版白皮书更加关注产业数字化与数据运营的带动价值,进一步加强了对数字经济新基础设施建设、营商环境及应急管理等城市服务和治理等热点方面的考察,形成了对中国城市数字经济发展更为系统全面的认知。
城市数字经济百城排名出炉 沪京深成杭领跑前五
在2019版白皮书中,中国城市数字经济百城排名榜单中,上海以89.8分卫冕第一,北京89.4分,由2018年的第三位上升至第二位,与深圳、成都、杭州共同领跑前五。值得一提的是,重庆以75.4分首次位列百城前十,在城市服务和城市治理领域表现突出,尤其在营商环境等领域优势明显,数字经济在重庆市的工业、服务业转型方面促生成效显著,已然成为“智能政府中枢”发展典范。

最新研究发现,探索城市数字经济发展之路
对于中国城市数字经济的发展,新华三也提出了全新的观察和发现。
发现一:中国城市数字经济呈现蓬勃发展之势
新华三数字经济研究院测算,2018年中国数字经济规模已达到33.16万亿元,在国民生产总值中所占比重为36.83%。
整体上数字经济依然沿着传统经济由东南向西北区域渗透的模式发展,以成都、重庆为代表的西南地区产业数字化加速发力,逐步衍生为中国数字经济“第四极”,以呼和浩特、鄂尔多斯、榆林为代表的呼榆城市群逐渐形成西北部“新高地“。
发现二:数字经济在部分领域重点突破
在数据及信息化基础设施方面,“信息基础-数据基础-运营基础” 为核心的“数字经济新基础设施”实现快速提升;城市服务方面,营商环境数字化改革创新力度加大;以信用、环保为抓手的城市治理能力提升;产业数字化成为数字经济主要驱动力。
发现三:“3+4+2”模式雏形初成
基于当前数字经济发展水平,各城市已在实践中逐渐形成3类方向定位,4条发展路径。
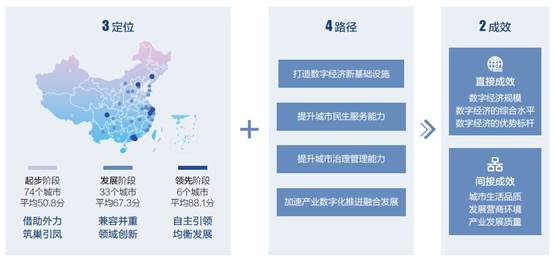
发现四:数字经济发展建设下沉,县域内生需求突出
目前的县域数字经济发展需求突出,基础设施较为薄弱,强调数字经济在本地的特色化发展,且产业数字化建设不均衡。
数据驱动为本,智取未来
“未来,中国城市数字经济发展要以数据驱动、融合应用、科学发展为方向,探索长效、高价值的运营机制。”新华三集团副总裁、解决方案部总裁李立建议。数据驱动,即对数据这一数字经济源动力的关注点,从“数据汇聚”提升到“数据治理”;同时,充分实现数据共享,并以业务需求为导向,打造数据、技术、业务三融合的数字经济新应用;此外,围绕城市特色,科学选择数字经济发展路径,以“3大定位、4大路径”为大方向,分城施策。
新华三一直躬耕于数字经济建设一线,并以此沉淀出了新华三智慧城市建设的理论体系,通过数字经济和智慧城市的有机结合,全力打造城市数字大脑计划,赋能百行百业的数字化转型。未来,新华三将持续赋能城市数字经济,助力数字中国的全面实现!
了解更多《中国城市数字经济指数白皮书(2019)》相关信息,敬请访问:http://deindex.h3c.com/
好文章,需要你的鼓励


现代汽车工厂工人因人形机器人部署计划罢工
韩国现代汽车工厂数千名工会工人因机器人部署谈判破裂,提前结束班次并发起罢工,成为有组织劳工针对人形机器人自动化浪潮最具影响力的抵制行动。工会要求将计件工资改为固定薪资,并将退休年龄从60岁提至65岁。现代计划在旗下工厂部署逾2.5万台Atlas人形机器人,每台造价约13万美元,预计两年内回本,其运营成本或将低于美国最低工资标准。

腾讯混元推出“又快又强“的轻量级文字识别大模型HunyuanOCR-1.5
腾讯混元联合中科院与南开大学推出的HunyuanOCR-1.5,通过DFlash推测解码实现最高6.37倍推理加速,并用智能体数据构建框架显著增强古文字、低资源语言、多图问答等长尾OCR能力。

欧盟正式要求谷歌开放搜索数据并允许安卓系统接入竞争性AI
欧盟依据《数字市场法》(DMA)对谷歌发布新规,要求其在Android平台向第三方AI助手开放更深层系统集成权限,打破Gemini的垄断优势;同时强制谷歌以合理费用向竞争对手共享搜索数据,以削弱其搜索市场主导地位。谷歌表示强烈反对,称此举威胁用户隐私与国家安全。谷歌须于2027年1月起共享搜索数据,2027年7月前完成Android平台开放改造。

沉睡的“孪生大脑“被唤醒:冲绳科学技术大学院大学的研究者们找到了让AI视觉学习更聪明的秘密
冲绳科学技术大学院大学研究者提出SiamJEPA,在JEPA框架中引入孪生学生编码器,证明其充当正则化器、加速训练并提升图像表示质量。
2019
04/19
23:05
分享
点赞

脑部植入物助瘫痪男子重获进食与饮水能力
能源公司IPO融资创21世纪新高,押注AI基础设施热潮
Apple Intelligence获中国监管批准,携手阿里巴巴与百度正式进入中国市场
Moonshot即将发布的Kimi K3有望赶超Anthropic Opus 4.8
OpenAI 为何开始卖 ChatGPT 品牌篮球?
DoorDash推出命令行工具,开发者可借助AI智能体直接下单
Google AI模式新增应用集成功能,支持Instacart等多款常用应用
Beehiiv推出社区互动功能并上线AI写作助手
英国警方:两名黑客被捕重创知名黑客组织"散落蜘蛛"
谷歌将NotebookLM更名为Gemini Notebook,强化生态系统整合
NASA阿尔忒弥斯计划经验如何应用于AI基础设施规划
如何禁止AI聊天机器人收集你的数据用于模型训练
