
华为云智能边缘平台IEF公测,让智能触手可及
万物智能的时代,越来越多企业希望在靠近物或者数据源头的边缘侧使用智能边缘服务,让联接更敏捷,业务高实时,减少云和网络的束缚。据IDC研究显示,到2020年将产生500亿的终端与设备联网,其中50%的数据将会在网络边缘侧分析处理。
日前,华为云智能边缘平台IEF正式开放公测,IEF通过使能端、边侧的计算资源,将华为云AI能力延伸到边缘侧,将边缘节点智能化。随着连接设备的爆炸性增长,以及用户对隐私、机密性、低延迟和带宽限制的需求,企业可以采用云上AI模型训练、边缘模型推理、预测执行的模式,既满足了实时性的要求,同时大幅降低无效数据上云。

IEF服务已率先应用到多个场景如智慧园区、智能制造等。在某智慧园区项目中,通过在边缘侧实现视频智能预分析,运用于深度学习人脸检测与人流分析,云端定义大数据流处理、模型训练等,将海量数据本地消化,避免大量数据回传带来的带宽浪费和时延,降低园区运营成本60%以上。在某梯联网项目,通过IoT设备管理,帮助电梯企业快速完成设备接入云端,配套云端大数据、AI能力,使得电梯具备更强的智能能力。
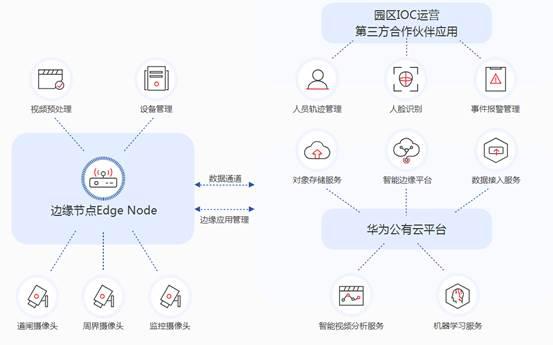
华为云智能边缘平台IEF,具备灵活易用、功能强大、生态开放等显著优势,满足客户对边缘计算资源的远程管控、数据处理、分析决策、智能化的诉求,为用户提供完整的边缘和云协同的一体化服务。
灵活易用:
华为云智能边缘平台IEF边云生态一致,无论在边缘和华为云保持一样的使用体验,基于同一个云平台,应用和服务构建一次,运行无处不在。Cloud Native的边缘计算平台,边云生态统一,支持容器、微服务、Kubernetes生态以及云服务边缘延伸等,支持应用快速开发、部署,降低应用开发部署成本。
模块化设计,对边缘计算资源的适配,最大限度地容纳用户已有资源和设备,用户可以根据自己的业务需要通过Docker容器技术模块化部署应用。
丰富的边云通信方式 ,提供基于消息(如MQTT)、REST、Streaming的消息通道,满足多种数据上云要求。
支持ARM/x86架构,支持工业网关、工控机等部署,最小可低至256M内存的边缘设备。
功能强大:
•丰富的边侧智能能力,华为全栈AI能力无缝延伸到边缘。比如利用华为在视频领域的积累,提供完善、高效的边缘视频AI能力。
•自研的AI芯片,通过软硬一体的优化结合,提供强大的边缘侧计算能力。
•提供边缘函数管理,基于Serverless架构的边缘快速响应本地事件。基于事件触发函数,提高边缘节点资源利用效率以及响应时间,同时简化设备编程模型以及边缘应用构建成本。
•提供智能边缘平台IoT设备管理能力,提供多种协议,支持IoT数据快速接入云端,让企业聚焦面向垂直行业的应用开发,帮助企业应用快速孵化。
生态开放:
华为具备完整的端、边、云一体化服务能力,通过IEF可以无缝利用华为云丰富的服务能力。
支持第三方边缘节点、设备和服务接入。通过第三方设备“兼容性认证”计划,通过标准化设备定义和接入方式,方便对接各类设备。支持第三方边缘应用/服务接入,快速构建面向行业的边缘智能应用。
边缘计算产业联盟(Edge Computing Consortium,缩写为ECC)ECC联盟的发起者,在工业领域有丰富的垂直行业ISV合作伙伴,与合作伙伴一起推动行业智能化发展。
开源边缘侧软件KubeEdge, 便于开发者对Runtime进行定制和裁剪,降低边缘的使用难度;
目前,智能边缘平台IEF在华为云官网上进行免费公测体验,点击链接可进入官网页面了解:https://www.huaweicloud.com/product/ief.html
好文章,需要你的鼓励


一次实验室意外或将彻底改变计算领域
研究人员意外发现,标准MOSFET晶体管可同时模拟神经元和突触行为,形成"神经突触随机存取存储器"(NSRAM)。该技术仅需一至两个晶体管即可实现传统需数十乃至数百个元件才能完成的神经信号处理,且与现有硅基制造工艺完全兼容,良率达100%。未来有望应用于边缘AI及高能效神经形态芯片,长远或可挑战GPU地位。

牛津大学让AI学会“物理直觉“:一个无需看视频就能预测物体运动的神经网络
牛津大学提出PHYSIFORMER,一种扩散变换器模型,通过三维网格顶点轨迹直接在世界坐标空间预测刚性与弹性物体的物理运动,一次性生成全序列轨迹,超越自回归基线。

借鉴生态学模型评估AI风险的新方法
本文提出一种评估人工智能风险的新方法,借鉴生态学与演化论视角,从理论生态模型中推导出三项风险指标,涵盖种群模型与生态系统模型。研究旨在为AI治理策略提供量化工具,并对分析局限性及政策改进方向进行了深入探讨,为构建更科学的AI风险评估体系提供参考框架。

奖励模型的“选择困难症“:卡内基梅隆大学与Meta联手发现AI训练中被忽视的隐患
研究发现主流奖励模型对同等质量答案给出差异悬殊的分数,并提出"奖励聚类"算法通过蒙特卡洛随机失活将连续分数离散化,在不重训模型的前提下有效减少AI训练中的奖励作弊现象。

