
数据库“祖传”架构难优化?华为云 MongoDB 社区增强版来帮忙,300% 性能提升
对 IOT 企业而言,IT 架构升级几乎是每个发展阶段都绕不开的坎。当公司飞速发展,在线业务迅猛增长,服务架构一次次承载冲击,高性能需求下,巨额成本也相伴而生。要处理翻倍的并发业务,接入层、后端的计算能力均需要加强,相应的缓存 IO 并发压力也只增不减。如何节省成本保持性能?其实关键点在于最底层的数据库上。
得益于灵活的数据结构和强大的集群扩展能力,文档数据库 MongoDB 分片集群架构常被选择作为发展中 IOT 企业的后端数据库。
传统 MongoDB 分片集群是典型的分布式架构,每个分片需要三个节点(Secondary)组成一个副本集提供多副本冗余。不但配置服务器(Config Server)需要耗费三个节点,而且每个分片(Shard Server)也都需要三个节点,且只有一个节点能写入。
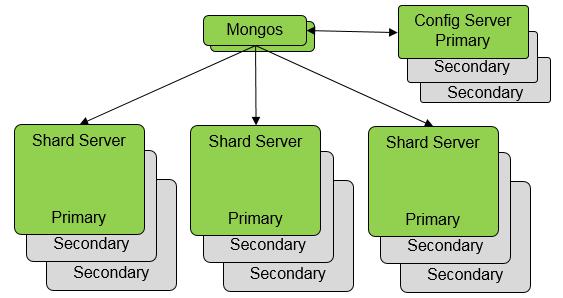
MongoDB 副本集基于 Raft 分布式一致性协议,其中包含了节点主备间选举、数据同步、Log 追加等技术细节,可以说是根正苗红。该架构优势明显:自动故障接管、数据三副本冗余,最重要的是稳定和可靠。因此对一般 DBA 而言,这种“祖传”架构,轻易根本不敢动。
然而,MongoDB 副本集架构也决定了其几乎先天的缺陷:提供三副本存储的同时,只有单节点可写,浪费了两个节点的计算能力。
那么,华为云近期推出的 MongoDB 社区增强版,是如何优化这祖传架构,将性能大幅提升的呢?
华为云 MongoDB 社区增强版关键技术
华为云 MongoDB 社区增强版带着优化传统架构、将性价比提升到极致的使命而生,保持三副本存储,每个节点提供读写能力,计算资源不浪费。其中的关键技术在业界更是处于领先地位。
放弃复制集,解放所有节点
华为 MongoDB 社区增强版将所有分片节点升级为 primary 提供读写能力,这样相较复制集的相同成本的计算节点,提供了三倍的计算能力。
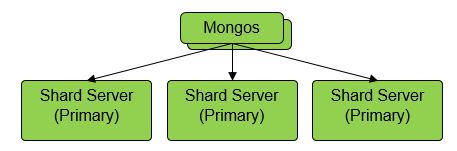
摒弃 “老传统“,节省了计算资源,那么如何保证数据的三副本?
存储计算分离,副本卸载到存储
在传统集群计算存储混合部署的方式中,我们期望越少的数据迁移以获得更高的资源利用率。然而在带宽不再稀缺,磁盘计算能力不断提升的今天,混合部署带来的木桶效应也相对明显,造成了集群资源的浪费。
华为云 MongoDB 社区增强版将存储与计算分离,存储层作三副本冗余,既保障了数据容灾的能力,又节省了计算成本。
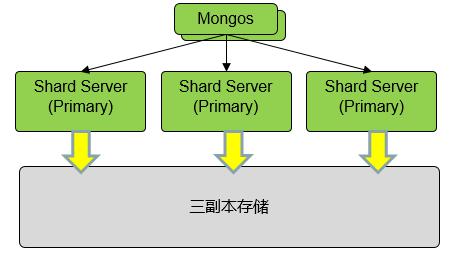
做到三副本冗余,节省了计算资源,还需要有故障接管的能力。
打破副本集,所有Shard Server相互扶持
三节点副本集中出现节点故障,会重新选出领导,领导副本集。当副本集中出现两个节点故障,整个副本集将无法工作。
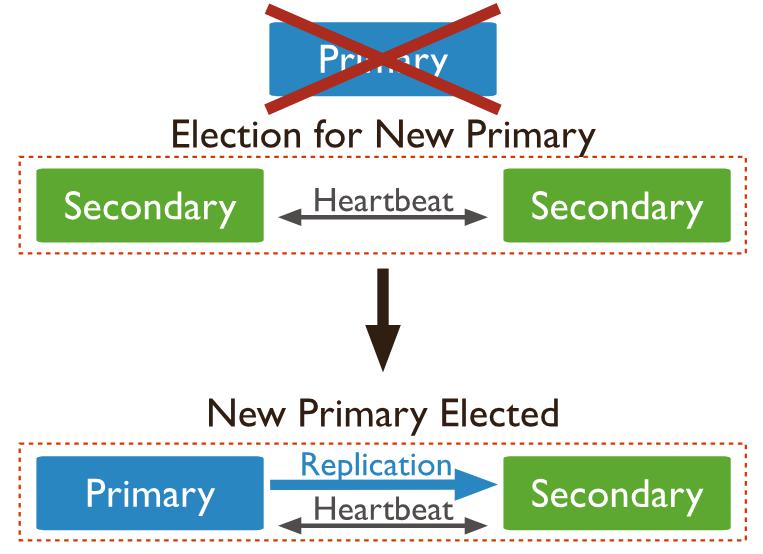
华为云 MongoDB 社区增强版节点间没有副本集主备关系,当一个 Shard Server 出现故障,其他 Shard Server会接管它的数据。
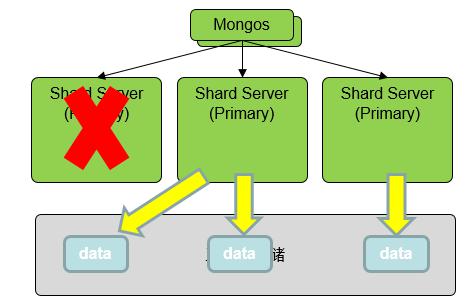
由于存储层数据共享,接管业务不需要迁移数据,只需要计算层节点从存储层加载对应数据即可。相比副本集中故障两个节点就无法工作,MongoDB 社区增强版集群在计算能力允许的情况下,可以容忍 N-1 个节点故障。
了解华为云 MongoDB 社区增强版更多信息,请移步官网:
https://activity.huaweicloud.com/dfv_mongo/index.html
来源:业界供稿
好文章,需要你的鼓励



北大学者带你拖拽3D物体,像玩拼图一样让虚拟世界动起来
北京大学团队开发的DragMesh系统通过简单拖拽操作实现3D物体的物理真实交互。该系统采用分工合作架构,结合语义理解、几何预测和动画生成三个模块,在保证运动精度的同时将计算开销降至现有方法的五分之一。系统支持实时交互,无需重新训练即可处理新物体,为虚拟现实和游戏开发提供了高效解决方案。

据说算力高达1000 TOPS,华硕Ascent GX10深度评测——模型推理
AI硬件的竞争才刚刚开始,华硕Ascent GX10这样将专业级算力带入桌面级设备的尝试,或许正在改写个人AI开发的游戏规则。

达尔豪斯大学团队重磅研究:为什么AI社会模拟需要从“沙盒游戏“升级为“开放世界“?
达尔豪斯大学研究团队系统性批判了当前AI多智能体模拟的静态框架局限,提出以"动态场景演化、智能体-环境共同演化、生成式智能体架构"为核心的开放式模拟范式。该研究突破传统任务导向模式,强调AI智能体应具备自主探索、社会学习和环境重塑能力,为政策制定、教育创新和社会治理提供前所未有的模拟工具。
2018
08/21
14:55
分享
点赞

据说算力高达1000 TOPS,华硕Ascent GX10深度评测——模型推理
上交联手阿里团队打造"AI记忆管家"ReMe,像人类一样从经验中学习
意大利航空携手ESA部署卫星通信技术提升飞行效率
苹果TV急需PoE支持以释放企业应用潜力
Google Translate为所有耳机带来实时语音翻译功能
生成式AI在心理健康咨询中的时间规律与人类使用习惯分析
回顾我们的2025年AI预测:准确性如何?
ServiceNow斥资10亿美元收购Veza 加速智能体权限管理
除英伟达和台积电外,其他AI公司都需要靠量补利
2025年数据中心芯片领域最热门发展趋势
自动化技术领导者揭示企业对AI认知的关键误区
五分之三企业对Wi-Fi投资信心增强
